Torch 部落格 
-
2016 年 7 月 25 日 語言模型一個十億個字
採用雜訊對比估計來訓練一個多 GPU 遞迴神經網路語言模型,資料集取自 Google 十億個字資料集。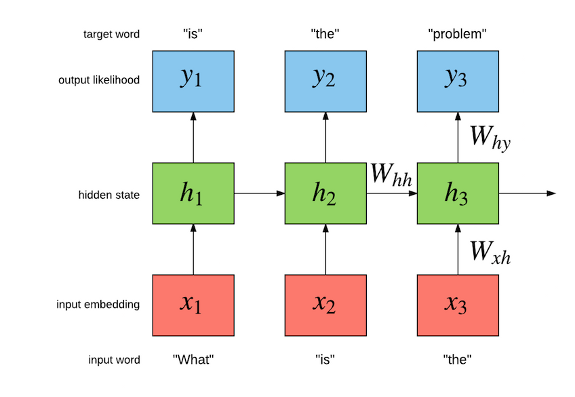 </img>
</img> -
2016 年 6 月 1 日 運用 OpenCV 和 Torch 的深度樂趣
在本文中,我們將結合 OpenCV 3.0 和 Torch,享受一些樂趣,來建立年齡和性別分類、神經藝術、神經對話和即時影像分類的實際範例。 </img>
</img> -
2016 年 4 月 30 日 決鬥式深度 Q 網路
在強化學習領域裡,深度 Q 網路已大幅躍進,在 Atari 2600 電玩遊戲領域裡,已達到人類無法達到的水準。在本文中,我們將說明它們如何運作,也會討論自 Google DeepMind 在自然期刊發表後的一些發展 - 特別是決鬥式 DQN。 </img>
</img> -
2016 年 2 月 4 日 訓練與研究殘差網路
在本文中,我們實作了深度殘差網路 (ResNets),並從模型選擇與最佳化層面探討 ResNets。我們也會討論訓練 ResNets 時的多 GPU 最佳化方法和工程範例。最後,我們將比較 ResNets、GoogleNet 和 VGG 網路。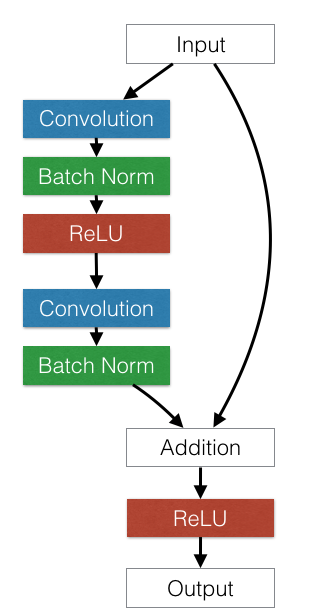 </img>
</img> -
2015 年 11 月 13 日 使用 Torch 產生人臉
在本文中,我們實作生成對抗網路 (GAN),並訓練它輸出人臉影像。GAN 非常難訓練,我們將探討一些讓收斂更穩定或更快速的技巧。此外,我們將結合 GAN 和變易自編碼器,得出一個能夠產生趣味影像的編碼器/解碼器架構! </img>
</img> -
2015 年 9 月 21 日 視覺注意力遞迴模型
視覺注意力模型最近在物體偵測和影像標題產生領域很成功。特別令人感興趣的是,這些模型具有人類般的注意力。在本文中,我們將討論遞迴注意力模型的實作,其中涉及一些強化學習,以及見解和程式碼。 </img>
</img> -
2015 年 9 月 7 日 空間轉換器網路的效力
空間轉換器是一種令人興奮、可學習的新層,能插入 ConvNets。我們展示,在 ConvNet 中使用這些層,我們能以更小的網路達到最新的準確度。我們也探索並視覺化轉換層中發生的學習狀況。 </img>
</img> -
2015 年 7 月 30 日 在 Torch 中達到 CIFAR-10 的 92.45%
CIFAR-10 是流行的視覺資料集,用來嘗試新想法。我們展示,使用批次正規化和類 VGG 的卷積神經網路架構的簡單組合,就能在資料集上取得有競爭力的基準。 </img>
</img>
</body> </html>