對決深度 Q 網路
深度 Q 網路 (DQN) [1] 重新點燃了神經網路在強化學習的應用,在充滿挑戰的電玩學習環境 (ALE) 基準測試中證明了其能力 [2]。ALE 是支援超過 50 款 Atari 2600 電玩的強化學習介面,使用單一架構和超參數選擇後,DQN 能在超過半數的電玩中獲得超越人類的得分。原始架構現已在若干進展的基礎下建構出更佳的架構,其中許多架構可以在 GitHub 上找到。由於 ALE 訓練可能需要 GPU 超過一週,因此代碼也設定為能夠在 CPU 上於數小時內學會玩較簡單的 接球 遊戲。
強化學習
最近的多數深度學習研究都集中在監督式學習,即尋找輸入資料 \(x\) 對應目標資料 \(y\) 的對應關係。具體而言,神經網路是參數化函數 \(f(x; \theta)\),我們透過使用誤差訊號來學習參數 \(\theta\)。非監督式學習涉及推論輸入資料的結構,沒有此類訊號,且可以使用許多方式來達成(例如分群)。另一方面,強化學習使用獎勵訊號,沒有從輸入資料到目標資料的明確對應關係,但目標是將它接收到的獎勵最大化。
在強化學習的情境中,代理程式必須藉由透過試誤與環境互動來學習。正式地,我們考量到環境有一組狀態 \(\mathcal{S}\),而代理程式有一組動作 \(\mathcal{A}\)。在每個離散時間步驟 \(t\) 中,代理程式會觀察環境狀態 \(s_t\) 並選取要執行的動作 \(a_t\)。接著,代理程式會接收一個純量獎勵 \(r_{t+1}\),並觀察下一個狀態 \(s_{t+1}\)。下方圖表顯示了這個動作感知迴圈。
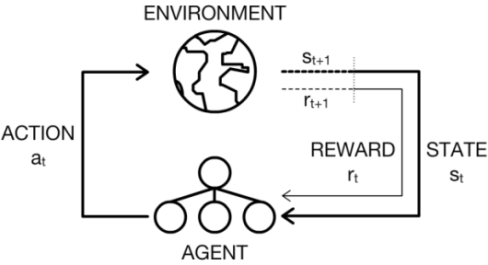
同時,代理程式尋求學習一個(控制)政策 \(\pi\),根據當前狀態使用這個政策來決定要執行的動作。最佳動作會讓其預期報酬 \(\mathbb{E}[R]\) 最大化,其中 \(R\) 定義如下:
\[R = \sum\limits_{t=0}^{T-1} \gamma^tr_{t+1}\]
在電玩遊戲的背景下,\(R\) 是某個章節 (直到玩家死亡) 中所有獎勵 (分數增加) 的總和,持續 \(T\) 個離散時間步驟(通常為個別的畫格)。我們也使用一個折扣變數,\(\gamma\),來決定代理的「遠見」如何 - 0 的值代表代理只關心接收到的下一個獎勵,而 1 的值代表它平均地關心未來接收到的每個獎勵。
解決強化學習問題的一種技巧是 Q 學習,這個技巧牽涉到學習一個動作價值函數
| \[Q(s, a) = \mathbb{E}[R | s, a]\] |
如果我們有最佳動作價值函數可以使用,那麼策略就會像取出一個動作一樣簡單,此動作會視代理的狀態在每個時間步驟中將函數極大化。但是,我們沒辦法使用最佳函數,因此我們必須嘗試從經驗中學習它。每次時間步驟,當代理執行一個動作時,它就會收到一個獎勵。目標是根據一個誤差,\(\delta\),以及一個學習率,\(\alpha\),來更新 \(Q\)
\[Q_{t+1}(s_t, a_t) = Q_t(s_t, a_t) + \alpha \delta\]
\(\delta\) 是 \(Q\) 的目前價值與目標 \(Y\) 之間的差異,而目標本身是接收到的獎勵加上下一個狀態的折扣最大 Q 價值
\[\delta = \left(r_t + \gamma\max_aQ_t(s_{t+1}, a)\right) - Q_t(s_t, a_t)\]
深度 Q 網路
回到深度學習,用深度神經網路來逼近 \(Q\),而不是精確地學習 \(Q\),這是很有道理的。事實上,神經網路在過去的強化學習問題中已經使用得很成功 [3],甚至使用 Q 學習 [4]。因此,對於玩 Atari 2600 電玩遊戲,如果我們想要從畫面上原始像素(環境的觀察狀態)學習,那麼從卷積神經網路 (CNN) 開始是有意義的,而這正是 DQN 所做的 [1]。我們也可以將動作的一熱編碼饋入神經網路,並在頂部從一個單元中取出 Q 值,但是有一個比較有效率的方法可以做到這件事。這是 DQN 的第一個竅門:他們只接受畫面作為輸入,並在頂部輸出每個可能動作的 Q 值。這不僅可以減少運算(與為每個動作執行網路相反),而且我們預期 DQN 的較低階卷積部分並不會受到動作的影響。這樣一來,較低階的部分可以專注於提取好的空間特徵,而具有完全連接層的較高階部分可以更專注於不同動作的後果。然後,網路架構就變得相當直接了當。
local net = nn.Sequential()
net:add(nn.View(histLen * nChannels, height, width)) -- Concatenate frames in channel dimension
net:add(nn.SpatialConvolution(histLen * nChannels, 32, 8, 8, 4, 4, 1, 1))
net:add(nn.ReLU(true))
net:add(nn.SpatialConvolution(32, 64, 4, 4, 2, 2))
net:add(nn.ReLU(true))
net:add(nn.SpatialConvolution(64, 64, 3, 3, 1, 1))
net:add(nn.ReLU(true))
net:add(nn.View(convOutputSize))
net:add(nn.Linear(convOutputSize, hiddenSize))
net:add(nn.ReLU(true))
net:add(nn.Linear(hiddenSize, m)) -- m discrete actions
DQN 訓練演算法中十分重要的元件,是一種稱為經驗重播的機制 [5]。透過與環境互動所經歷的轉換會儲存在經驗重播記憶體。接著,會從這些轉換中均勻取樣,以便使用離線方式進行訓練。從理論觀點來看,這會打破影響線上學習的強時間相關性。從更務實的角度來看,這不僅能重複使用資料,還能讓硬體以高效的方式使用小批次。
訓練演算法的另一項元件是目標網路。強固學習中函數逼近可能並不穩定,因此目標網路用於為問題加入一些穩定性。當政策網路進行動作時,會使用更新較為緩慢的目標網路對 \(Y\) 進行評估。目標網路僅包含政策網路舊版本的權重,且會在大量常數步驟後更新。
訓練視覺化
下列其中一篇論文 [6] 使用醒目標記圖 [7] 的概念,觀察網路關注在何處。這在強化學習設定中特別有趣,因為它讓我們得以找出代理程式有關於當前狀態的行為的可解釋性。以下是使用引導反向傳播 [8] 拍攝的影片,提供稍微漂亮的醒目標記圖。
對抗網路架構
在強化學習中,優勢函數 [9] 可以定義如下
\[A(s, a) = Q(s, a) - V(s)\]
如果 \(Q(s, a)\) 代表在狀態 \(s\) 中選擇特定動作 \(a\) 的值,\(V(s)\) 代表與動作無關的狀態值。此特性引導出定義 \(V(s) = \max_aQ(s, a)\)。因此,\(A(s, a)\) 提供在 \(s\) 中動作實用性的相對測量。對抗網路架構 [6] 背後的見解是,有時確切的動作選擇並不那麼重要,因此,更能明確模擬狀態,而與動作無關。另一個優勢是,當在強化學習中自舉(使用估計值來學習)時,能對 \(V(s)\) 進行良好估算便有助於學習。因此,此函數可以建構在網路的架構中(就像 ResNet)
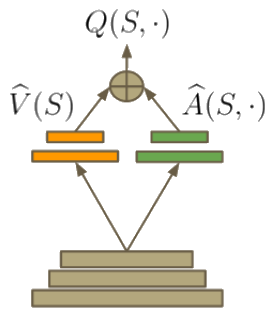
變更 DQN 程式碼時,您只需要用以下內容取代頂端的全連接層
-- Value approximator V^(s)
local valStream = nn.Sequential()
valStream:add(nn.Linear(convOutputSize, hiddenSize))
valStream:add(nn.ReLU(true))
valStream:add(nn.Linear(hiddenSize, 1)) -- Predicts value for state
-- Advantage approximator A^(s, a)
local advStream = nn.Sequential()
advStream:add(nn.Linear(convOutputSize, hiddenSize))
advStream:add(nn.ReLU(true))
advStream:add(nn.Linear(hiddenSize, m)) -- Predicts action-conditional advantage
-- Streams container
local streams = nn.ConcatTable()
streams:add(valStream)
streams:add(advStream)
-- Add dueling streams
net:add(streams)
-- Add dueling streams aggregator module
net:add(DuelAggregator(m))
aggregator 模組 聚合器模組 稍為複雜,不過可以使用 Torch 的標準資料表容器建構。
訓練
如先前所述,在 ALE 上進行訓練可能需要超過一週的時間才能完成。快速測試比較適合的遊戲是 Pong,因為它應該能在約 1/10 的正常訓練週期中(通常在 GPU 上進行一天)達到完美或接近完美的結果。對那些想要看到更立即結果的人來說,該程式碼也設定好可以玩 Catch - 一個 24\(\times\)24 像素的黑白環境,代理程式在底部的球拍必須接住一個掉落的球。
結果
以下我們可以看到原始 DQN、雙重 DQN (DDQN) [10](使用 Q 學習更新規則的改良版)以及在 Space Invaders 中的對戰 DQN 之間的差異。與原始論文相同的是,對戰 DQN 也使用與 DDQN 相同的更新規則。
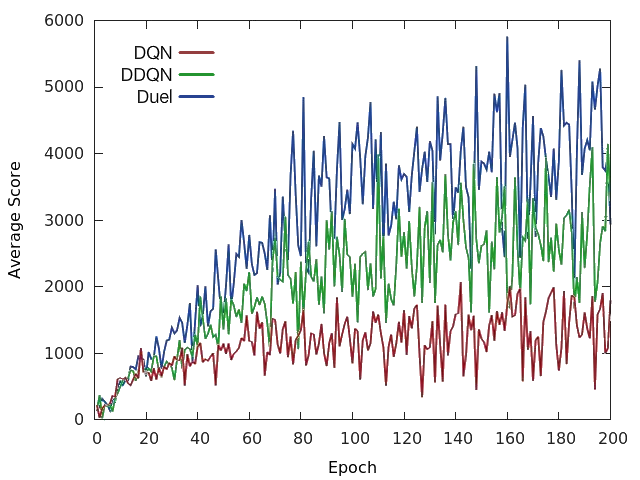
整體而言,對戰網路架構在幾乎所有遊戲中都比原始 DQN 和 DDQN 取得更好的效能 [6]。更重要的是,這個概念可以與 DQN 上的其它進展一起使用,表示它可以只當作一個成功深度強化學習代理程式的其中一個組成部分。
結論
這篇文章探討了 DQN 如何在高維度視覺領域中學習成功的策略,而且可以透過純粹的架構新增而變得更強大。它也研究了 CNN 視覺化技術如何被用來瞭解 DQN 的動作。
致謝
感謝 DeepMind 釋出他們的原始程式碼 [1],做為參考之用。
感謝 Laszlo Keri 和其他對 儲存庫 有所貢獻的人。
參考文獻
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., … & Petersen, S. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529-533.
- Bellemare, M. G., Naddaf, Y., Veness, J., & Bowling, M. (2013). The Arcade Learning Environment: An Evaluation Platform for General Agents. Journal of Artificial Intelligence Research, 47, 253-279.
- Tesauro, G. (1994). TD-Gammon, a self-teaching backgammon program, achieves master-level play. Neural computation, 6(2), 215-219.
- Riedmiller, M. (2005). Neural fitted Q iteration–first experiences with a data efficient neural reinforcement learning method. In Machine Learning: ECML 2005 (pp. 317-328). Springer Berlin Heidelberg.
- Lin, L. J. (1992). Self-improving reactive agents based on reinforcement learning, planning and teaching. Machine learning, 8(3-4), 293-321.
- Wang, Z., de Freitas, N., & Lanctot, M. (2015). Dueling Network Architectures for Deep Reinforcement Learning. arXiv preprint arXiv:1511.06581.
- Simonyan, K., Vedaldi, A., & Zisserman, A. (2013). Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv preprint arXiv:1312.6034.
- Springenberg, J. T., Dosovitskiy, A., Brox, T., & Riedmiller, M. (2014). Striving for simplicity: The all convolutional net. arXiv preprint arXiv:1412.6806.
- Baird III, L. C. (1993). Advantage updating (No. WL-TR-93-1146). Wright Lab Wright-Patterson AFB OH.
- 范哈塞爾特、安德烈‧格茲、大衛‧西爾弗(2015)。深度強化學習與雙 Q 學習。arXiv 預印本 arXiv:1509.06461。