訓練和探究殘差網路
本文由 Facebook AI 研究中心的 Sam Gross 和 CornellTech 的 Michael Wilber 共同撰寫。
在本文中實作深度殘差網路 (ResNet),並從模型選擇與最佳化觀點探討 ResNet。同時,也探討多 GPU 最佳化和訓練 ResNet 的技術最佳做法。最後,將 ResNet 與 GoogleNet 和 VGG 網路進行比較。
我們在 GitHub 釋出訓練程式碼,以及已預先訓練的模型供您下載,並提供針對您自己的資料集進行微調的說明。
我們釋出的已預先訓練模型的精確度高於原始論文中的模型。
簡介
去年底,Microsoft Research Asia 發表一篇名為「影像辨識的深度殘差學習」的論文,作者為何凱明、張祥雨、任少卿和孫建。此論文在影像分類與偵測方面取得最先進的成果,榮獲 ImageNet 與 COCO 競賽。
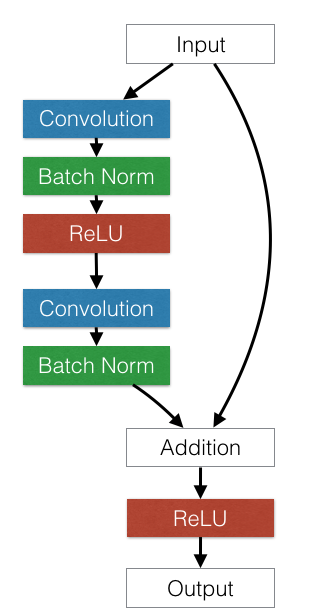
論文的核心概念既簡單又具美感。他們採用標準前饋式 ConvNet,並加入跳躍連線,一次跳過 (或捷徑) 少數幾個卷積層。每個跳躍產生一個 殘差區塊,其中卷積層會預測殘差,並將其加入區塊的輸入張量。
下圖顯示一個殘差區塊範例。
深度前饋式卷積網路往往會有最佳化上的困難。超過一定深度後,增加額外層數會導致較高的訓練錯誤和驗證錯誤,即使在使用批次標準化的情況下也是如此。ResNet 論文的作者認為,這種欠擬合不太可能是由消失梯度所導致,因為即使在使用批次標準化網路的情況下,也會發生這種困難。殘差網路架構透過加上與卷積層輸出相加的捷徑連線,來解決這個問題。
本文提供了一些資料點,供讀者從最佳化的觀點更深入地了解殘差網路。同時也會探討某些設計決策對所建構網路的效能有哪些貢獻。
論文在 Arxiv 上發表後,我們兩位本文作者都獨立地開始探究並重現該論文的成果。在了解彼此的研究成果後,我們決定共同撰寫一篇文章,結合我們的經驗。
消融研究 (在 CIFAR-10 上)
當試著了解複雜的機器,例如殘差網路時,執行大規模的探索性研究(例如針對 ImageNet 資料集)可能會很麻煩,這是因為訓練一個完整的模型需要好幾天才會收斂。因此,在較小的資料集上執行消融研究通常會有幫助,因為可以獨立測量模型每個面向的影響。如此一來,我們就能快速找出研究中哪些部分是最重要的,並在後續開發時專注於這些部分。在設計完整的系統時,快速的周轉時間以及持續的驗證會有所幫助,因為被忽略的細節最終常會帶來問題。
針對這些實驗,我們複製了殘差網路論文的第 4.2 節,並使用 CIFAR-10 資料集。在此設定中,一個含有 20 個層數的小殘差網路需要大約 8 個小時才能在 Amazon EC2 g2.2xlarge 執行個體上收斂 200 個週期。一個較大的 110 層網路需要 24 小時。這仍然很長,但是因為如果程式碼沒有錯誤,訓練損失應該會快速降低(在訓練開始後的幾分鐘內),所以通常會立即發現會阻止收斂的重大錯誤。
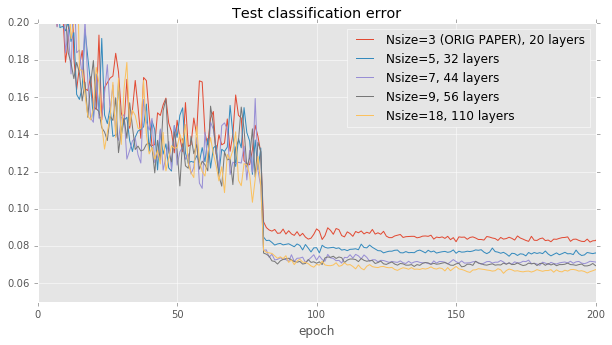
模型深度影響。殘差網路論文提供了一個自然的起點來比較:論文中的圖 6 只是單純地測量準確度與網路深度之間的相關性。為了複製此圖,我們固定學習率策略和建構塊架構,同時改變網路中層數的數量,範圍從 20 到 110。我們的結果與論文中的結果非常接近:準確度與模型大小相關,但在大約 40 層之後會變平穩。
殘差區塊架構。
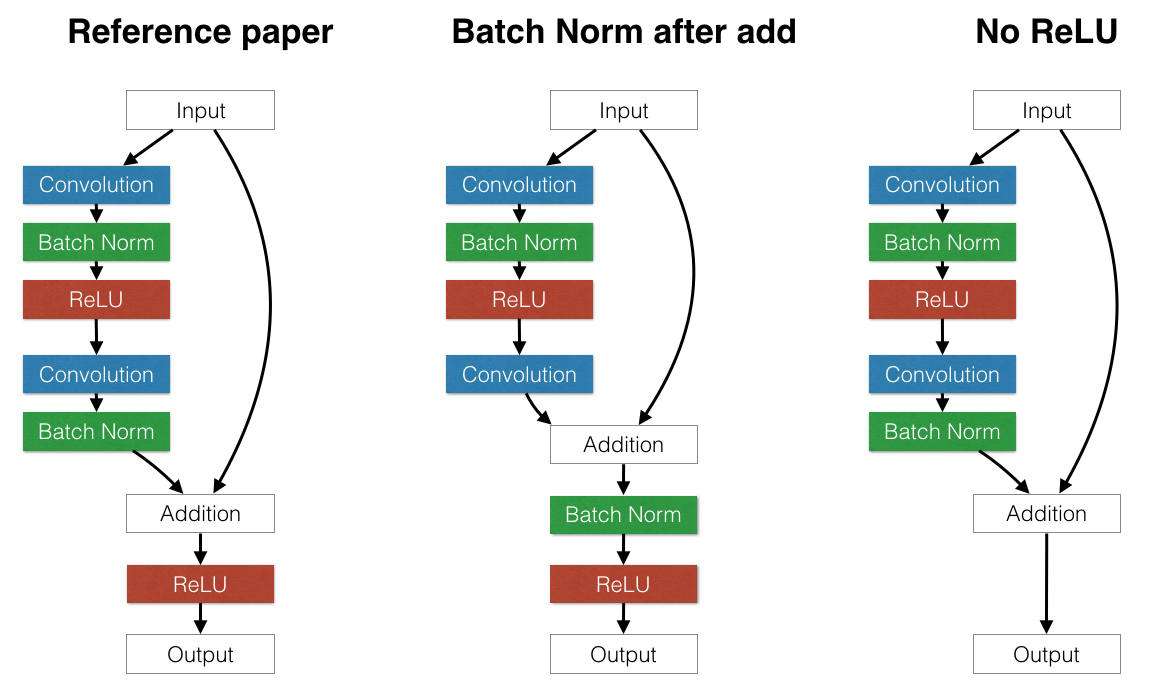
在驗證我們的結果與原始論文非常接近之後,我們開始考慮略微不同的殘差區塊架構的影響,以測試模型的假設。例如
-
是否將批次正規化放在每個殘差區塊結束時的加法之後或之前比較好?如果將批次正規化放在加法之後,它會產生正規化整個區塊輸出的效果。這可能會帶來好處。但是,這也迫使每個跳接連接擾動輸出。這可能會有問題:有些路徑允許資料在其他處理之前通過數個連續的批次正規化層。每個批次正規化層都會運用自己獨立的扭曲,這會複雜化原始輸入。這會產生一個有害的效果:我們發現將批次正規化放在加法之後會明顯損害 CIFAR 上的測試誤差,這符合原始論文的建議。
-
上述結果似乎表示盡量避免變更只有身分連結通過的資料十分重要。我們可以更進一步實施這項原理:我們是否應移除每個殘差區塊最後的 ReLU 層?ReLU 層也會擾亂通過身分連結流動的資料,但與批次正規化不同,ReLU 的冪等性表示無論資料通過一個或三十個 ReLU 都無所謂。當我們移除每個建構區塊最後的 ReLU 層後,我們觀察到測試效能有小幅進步,與論文建議在加總後置入 ReLU 的寫法相比。不過,改善幅度相當小。需要進一步探索。
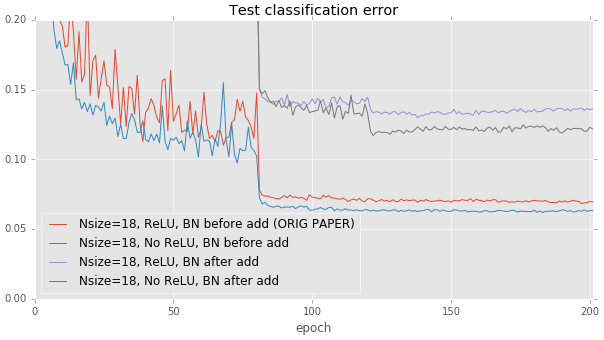
這些結果是在較深的 110 層模型上運作。在較淺的 20 層基礎線上,其影響較不明顯。
備用最佳化程式。在執行超參數搜尋時,嘗試比動量法香草隨機梯度下降法更花俏的最佳化策略,通常會有所回報。做出細微假設的更花俏最佳化程式可能會改善訓練時間,但也可能更難訓練這些非常深入的模型。在我們的實驗中,我們將動量法隨機梯度下降法(論文原始文件使用的方法)與 RMSprop、Adadelta 和 Adagrad 做比較。許多方法一開始看起來收斂得較快(見下方的訓練曲線),但最終,動量法隨機梯度下降法的測試誤差比次佳策略低 0.7%。
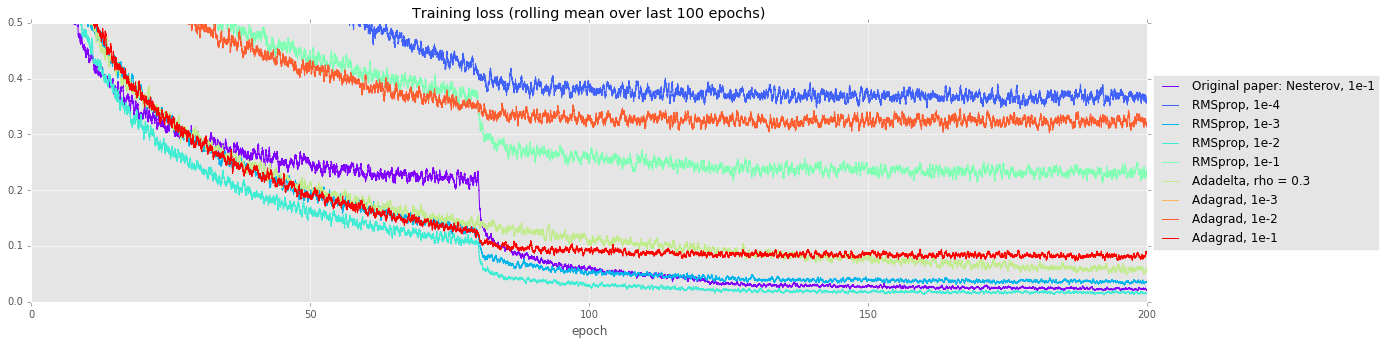
| 求解器 | 測試誤差 |
|---|---|
| N 大小=18,原始文件:Nesterov,1e-1 | 0.0697 |
| N 大小=18,最佳 RMSprop(學習率 1e-2) | 0.0768 |
| N 大小=18,Adadelta | 0.0888 |
| N 大小=18,最佳 Adagrad(學習率 1e-1) | 0.1145 |
這些實驗有助於驗證模型的正確性,並找出一些未來工作的有趣方向。不過,轉移到更大的 ImageNet 資料集後,引發了本身一大堆有趣的挑戰。
使用更大規模進行訓練:ImageNet
我們訓練了 18、34、50 和 101 層 ResNet 模型的變體,並在 ImageNet 分類資料集上執行訓練。值得注意的是,我們使用不同的資料擴增方法,達到的誤差率比已發表的結果更好。
我們也正在訓練一個 152 層的 ResNet 模型,不過模型在本文發布時尚未收斂完成。
我們採用「使用對卷積做更深入探討」中說明的縮放和長寬比擴增,而非 ResNet 論文中說明的縮放擴增。使用 ResNet-34,這樣改善了大約 1.2% 點的最佳驗證誤差。我們也採用了「深層卷積神經網路影像分類的一些改進」中說明的色彩擴增,但發現其對 ResNet-34 的影響非常小。
模型變更
我們實驗將批次正規化層從建構區塊最後一個卷積的後面移到加總之後。我們也嘗試將瓶頸架構(ResNet-50 和 ResNet-101)中的步伐二降採樣從第一個 1x1 卷積移到 3x3 卷積。
| 模型 | 批量層標準化 | 步長為二的層 | Top-1 單一 crop 誤差 (%) |
|---|---|---|---|
| ResNet-18 | 通過卷積後 | 3x3 | 30.6 |
| ResNet-18 | 通過加法後 | 3x3 | 30.4 |
| ResNet-34 | 通過卷積後 | 3x3 | 26.9 |
| ResNet-34 | 通過加法後 | 3x3 | 27.0 |
| ResNet-50 | 通過卷積後 | 3x3 | 24.5 |
| ResNet-50 | 通過加法後 | 1x1 | 24.5 |
| ResNet-50 | 通過加法後 | 3x3 | 24.2 |
批量標準化
Torch 使用指數移動平均值計算推理中批量標準化層所使用的均值和變異數估計值。預設情況下,Torch 對移動平均值使用平滑因子 0.1。我們發現將平滑因子減小到 0.003 並重新計算均值和變異數將 Top-1 錯誤率改善了約 0.2%。
多 GPU 訓練
使用 4 個 NVIDIA Kepler GPU 以及下方說明的最佳化,訓練的時長從 18 層模型的 3.5 天到 101 層模型的 14 天。
為了加速訓練,我們使用
4 個 GPU 上的資料平行性:這是一種加速訓練深度學習模型的標準方法。輸入是 N 個樣本的小批量,這些樣本被分為 N/4 個子批量,然後分別傳送至每個 GPU 進行訓練,並且在此過程中通過 GPU 傳遞網路參數。在 Torch 中,可以使用 nn.DataParallelTable 執行此操作。
透過 CuDNN-4 的 FFT 卷積:使用 CuDNN Torch 繫結,可以透過設定 cudnn.fastest 和 cudnn.benchmark 為 true 來選擇最快的卷積核。這會自動在您的 GPU 上對每種可能的演算法進行基準測試,並選擇最快的演算法。這將每小批次的時間縮短了(在單一 GPU 上 約 40%),但由於額外的核啟動開銷,會減慢多 GPU 案例的速度。
多執行緒核啟動:基於 FFT 的卷積需要多個較小的核,這些核會快速連續啟動。儘管 CUDA 核啟動是非同步的,但它們仍然會在 CPU 上花費一些時間進行佇列排程。使用 DataParallelTable 時,所有第一個 GPU 的核都會在第二、第三和第四個 GPU 的任何核被佇列排程之前進行佇列排程。為了修復這個問題,我們為 DataParallelTable 導入了多執行緒模式,該模式使用每個 GPU 的一個執行緒來並行啟動核。
NCCL Collectives:我們還使用了 NVIDIA NCCL 多 GPU 通訊原語,這將訓練速度再提升了 4%。4% 可能聽起來微不足道,但舉例來說,在訓練 Resnet-101 時,這相當於節省了 13 小時。
GPU 記憶體最佳化
我們運用了一些技巧,得以將較大的 ResNet-101 和 ResNet-152 模型放入 4 個 GPU 中,每個 GPU 有 12 GB 的記憶體,同時還能使用批次大小 256(ResNet-152 的批次大小為 128)。在向後傳遞中,當模組的 gradWeight 已經算好時,就可以重複使用 gradInput 緩衝區。在 Torch 中,實現此功能的簡易方法是 修改同樣類型的模組,以分享它們的基本儲存。此外,我們也使用了 ReLU 和 CAddTable 模組中的就地變形。
加入這些記憶體最佳化功能,只會額外產生 10 行程式碼。
ResNet 與 GoogleNet 和 VGG-A/D 的速度
在影像分類脈絡中,有趣的是拿 ResNet 與其他最先進的 convnet 模型相比,看看它們在訓練 / 推斷時間方面的表現。我們使用 NVIDIA Titan X,測量了 ResNet、VGG A、VGG D、批次正規化 Inception 和 Inception v3 對 32 張影像的迷你批次執行一次完整前向和後向傳遞的時間。下面也列出了 ImageNet-2012 資料集的 top-1 單次裁切驗證誤差。
| 模型 | Top-1 err (%) | 時間 (毫秒) |
|---|---|---|
| VGG-A | 29.6 | 372 |
| VGG-D | 26.8 | 687 |
| ResNet-34 | 26.7 | 231 |
| BN-Inception | 25.2 | 192 |
| ResNet-50 | 24.0 | 403 |
| ResNet-101 | 22.4 | 649 |
| Inception-v3 | 21.2 | 494 |
在效率方面,ResNet 肯定比牛津大學的 VGG 模型有所進步,但就準確度 / 每毫秒比例來說,GoogleNet 似乎還是較為有效率。
程式碼釋出
我們將釋出用以訓練 ResNet 的程式碼,讓其他人也可以使用自己的資料集進行訓練。在 https://github.com/facebook/fb.resnet.torch 中,可以找到用於在 ImageNet 上訓練 ResNet 的程式碼。這也包括在 CIFAR-10 上進行訓練的選項,而且我們還說明如何訓練 ResNet 以使用各位自己的資料集。
CIFAR-10 消融研究的程式碼在 https://github.com/gcr/torch-residual-networks。
預訓練模型
我們將釋出 ResNet-18、34、50 和 101 模型,讓社群中的每個人都能使用。我們希望這將有助於加速社群中的研究。訓練完成後,我們將釋出 152 層模型。
預訓練模型可在 此連結取得,並且包含說明,供您在自己的資料集上微調。
我們模型的準確度高於原始的 ResNet 模型,這很有可能是因為加入了長寬比增加。下表比較了原始 ResNet paper 和我們釋出的模型之間單次裁切 top-1 驗證錯誤率。
如您所見,我們的 ResNet-101 模型比 MSR-A 的 ResNet-152 模型獲得更高的準確度。我們並未大幅調整我們模型對應的驗證錯誤,所以並沒有過度貼合驗證組。事實上,我們只訓練過一次 ResNet-101 模型,而且沒有進行任何超參數掃描。
| 模型 | 原始 top-1 err (%) | 我們的 top-1 err (%) |
|---|---|---|
| ResNet-50 | 24.7 | 24.0 |
| ResNet-101 | 23.6 | 22.4 |
| ResNet-152 | 23.0 | 不適用 |
結論
我們已提供針對深度殘差神經網絡訓練的模型選取、最佳化,以及工程最佳化的研究。我們釋出了最佳化的訓練程式碼以及預先訓練的模型,希望此舉可讓社群受益。
#####################################################################################################################
致謝
感謝何愷明在原始論文中討論模稜兩可且遺漏的細節,並協助我們重製結果。
感謝 Ross Girshick、Piotr Dollar、林宗毅和 Adam Lerer 的討論。
感謝 Natalia Gimelshein、Nicolas Vasilache 和 Jeff Johnson 提出關於多 GPU 最佳化程式碼和討論。
參考資料
[1] 何愷明等人。「用於影像辨識的深度殘差學習。」arXiv 預印本 arXiv:1512.03385(2015 年)。
[2] Ioffe, Sergey,以及 Christian Szegedy。「批次標準化:透過減少內部協變位移加速深層網路訓練。」arXiv 預印本 arXiv:1502.03167(2015 年)。
[3] Simonyan, Karen,以及 Andrew Zisserman。「用於大規模影像辨識的極度深層卷積網路。」arXiv 預印本 arXiv:1409.1556(2014 年)。
留言由 Disqus 提供