視覺注意力遞迴模型
在此篇部落格文章中,我想討論我們在 Element-Research 如何實作 [1] 中所述的遞迴注意力模型 (RAM)。我們不只能重現論文,也可以在過程中提供許多模組化程式碼。你可以使用下列 訓練指令碼 在 MNIST 資料集上重現 RAM。我們將在此篇文章中使用該指令碼的片段。然後,你可以使用 評量指令碼 評估你訓練好的模型。
此論文描述了可套用於影像分類資料集的 RAM。該模型以一種方式設計,其中它有一個輸入影像的頻寬受限感測器。例如,如果輸入影像的大小是 28x28 (高 x 寬),RAM 可能只在任何給定的時間步長感測大小為 8x8 的區域。這些小感測區域稱為瞥視。
空間瞥視
實際上,論文的瞥視感測器比我們在上面描述的再複雜一點,但仍然簡單。秉持著 Torch7 的 nn 套件的模組化精神,我們建立了 SpatialGlimpse 模組。
module = nn.SpatialGlimpse(size, depth, scale)
基本上,如果你提供影像給它,像是經典的 3x512x512 Lenna 圖片

並且在該圖片上執行這段程式碼
require 'dpnn'
require 'image'
img = image.lena()
loc = torch.Tensor{0,0} -- 0.0 is the center of the image
sg = nn.SpatialGlimpse(64, 3, 2)
output = sg:forward{img, loc}
print(output:size()) -- 9 x 64 x 64
-- unroll the glimpse onto its different depths
outputs = torch.chunk(output, 3)
display = image.toDisplayTensor(outputs)
image.save("glimpse-output.png", display)
最後你會得到下列(展開)瞥視

雖然輸入是 3x512x512 的圖片(786432 個純量),輸出卻很小:9x64x64(36864 個純量),大約是原始影像大小的 5%。由於此處的瞥視具有 depth=3(即它會使用 3 個修補程式),每個相繼的修補程式都是前一個修補程式大小的 scale 倍。因此,最後我們會得到一個小區域的高解析度修補程式和面積更大的低解析度(即縮放)修補程式。這與我們人類的注意力機制可能的運作方式產生令人著迷的類比。人類通常可以生動地看到我們注意力焦點的細節,同時仍然維持周圍環境模糊的感覺。
儘管對於複製本文來說沒有必要,SpatialGlimpse 也可以部分地向後傳播。可以獲得有關 img 張量的 w.r.t. 梯度,w.r.t. 的梯度 location(即「瞥視」的 x,y 坐標)將為零。這是由於瞥視操作無法區分 w.r.t.location。這讓我們了解到注意力模型的主要難題:我們如何才能教導網路瞥視正確的 locations?
強化 REINFORCE 演算法
一些注意力模型使用完全可微分的注意力機制,如最近的 DRAW 論文 [2]。但 RAM 模型使用不可微分的注意力機制。具體來說,它使用 REINFORCE 演算法 [3]。此演算法允許使用強化學習訓練隨機單元。
REINFORCE 演算法功能強大,可用於最佳化隨機單元(基於輸入),以最小化目標函數(即獎勵函數)。與反向傳播 [4] 不一樣,這個目標不需要是可微分的。
RAM 模型使用 REINFORCE 演算法訓練 locator 網路
-- actions (locator)
locator = nn.Sequential()
locator:add(nn.Linear(opt.hiddenSize, 2))
locator:add(nn.HardTanh()) -- bounds mean between -1 and 1
locator:add(nn.ReinforceNormal(2*opt.locatorStd)) -- sample from normal, uses REINFORCE learning rule
locator:add(nn.HardTanh()) -- bounds sample between -1 and 1
locator:add(nn.MulConstant(opt.unitPixels*2/ds:imageSize("h")))
輸入是先前的遞迴隱藏狀態 h[t-1]。在訓練期間,輸出會從具有固定標準差的常態分配中取樣。平均值會根據 h[t-1] 透過仿射轉換(即 Linear 模組)進行制約。在評估期間,輸出會被視為輸入,也就是平均值,而不是從分配中取樣。
一個 ReinforceNormal 模組針對常態分配實作 REINFORCE 演算法。與大多數 Modules 不同,ReinforceNormal 在呼叫 backward 時會忽略 gradOutput。這是由於它所體現的單位實際上是隨機的。那麼,當呼叫 backward 時,它如何產生 gradInputs?它使用 REINFORCE 演算法,需要定義一個獎勵函數。本文所使用的獎勵非常簡單,但不可微分(等式 1)
R = I(y=t)
其中 R 為原始獎勵,I(x) 為當 x 為真時為 1,否則為 0(請參閱 指標函數),y 為預測類別,t 為目標類別。或在 Lua 中
R = (y==t) and 1 or 0
REINFORCE 演算法要求我們區分有關參數的分配的機率密度或質量函數 (PDF/PMF)。因此,給定下列變數
f:常態機率密度函數x:抽樣值(亦即ReinforceNormal.output)u:平均值(對ReinforceNormal的input)s:標準差(ReinforceNormal.stdev)
常態機率函數對平均值 u 的對數導數為
d ln(f(x,u)) (x - u)
------------ = -------
d u s^2
那麼 d ln(f(x,u,s) / d u 與獎賞搭配後,會變成什麼呢?嗯,為了取得獎賞 R 對輸入 u 的梯度,我們套用下列方程式(方程式 2,亦即 REINFORCE 演算法)
d R d ln(f(x,u))
--- = a * (R - b) * --------------
d u d u
其中
a(alpha) 只是一個縮放因子,就像學習率;而b是用來減少梯度變異的基準獎賞。f是機率質量函數 (PMF)/機率密度函數 (PDF)u是參數,而你想要取得其梯度x是抽樣值。
在論文中,他們讓 b 成為預期獎賞 E[R]。他們用使 b 成為模型的條件獨立參數來近似預期。對每一個實例,R 和 b 之間的均方差會透過反向傳播來極小化。這樣做的優點是,與例如讓 b 變成 R 的移動平均相比,基準獎賞 b 會以與模型其他部分相同的速率學習。
我們決定在 VRClassReward 標準中實現方程式 2 的一部分 reward = a * (R - b),它也實作了論文的變異減少分類獎賞函數(方程式 1)
vcr = nn.VRClassReward(module [, scale, criterion])
nn 套件主要建置用於反向傳播,因此我們必須找到一個不太偷吃步的方法,將 reward 廣播到不同的 Reinforce 模組。我們藉由讓損失函數將 module 視為引數,並新增 Module:reinforce(reward) 方法來達成此目的。後者讓 Reinforce 模組(例如 ReinforceNormal)可以保留損失函數廣播的 reward 來供日後使用。日後指的是呼叫 backward 時,Reinforce 模組會使用 REINFORCE 演算法計算 gradInput(即 d R / d U)。然後 nn 就會很高興,因為有了 gradInput,它可以繼續從 Reinforce 模組對其之前模組進行反向傳播。
所以總而言之,如果您能對機率質量函數/機率密度函數相對於其參數進行微分,就可以對其使用 REINFORCE 演算法。我們已經針對分類式和二項式分佈實作模組
遞歸注意模型
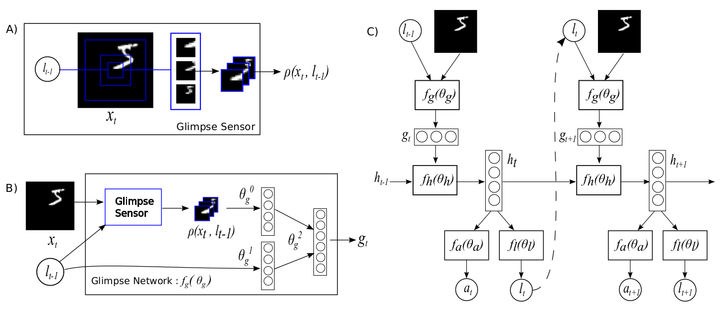
好,所以我們討論過一瞥模組和 REINFORCE 演算法,現在讓我們來談談遞歸注意模型。我們可以將模型分為其各個組成部分
定位感測器,其輸入為目前一瞥位置的 x、y 座標,因此網路會知道它每次時間步長都在看著哪裡
locationSensor = nn.Sequential()
locationSensor:add(nn.SelectTable(2))
locationSensor:add(nn.Linear(2, opt.locatorHiddenSize))
locationSensor:add(nn[opt.transfer]())
一瞥感測器,它是所看內容
glimpseSensor = nn.Sequential()
glimpseSensor:add(nn.DontCast(nn.SpatialGlimpse(opt.glimpsePatchSize, opt.glimpseDepth, opt.glimpseScale):float(),true))
glimpseSensor:add(nn.Collapse(3))
glimpseSensor:add(nn.Linear(ds:imageSize('c')*(opt.glimpsePatchSize^2)*opt.glimpseDepth, opt.glimpseHiddenSize))
glimpseSensor:add(nn[opt.transfer]())
一瞥網路,一瞥網路和定位感測器透過隱藏層混合形成遞歸神經網路 (RNN) 的輸入層
glimpse = nn.Sequential()
glimpse:add(nn.ConcatTable():add(locationSensor):add(glimpseSensor))
glimpse:add(nn.JoinTable(1,1))
glimpse:add(nn.Linear(opt.glimpseHiddenSize+opt.locatorHiddenSize, opt.imageHiddenSize))
glimpse:add(nn[opt.transfer]())
glimpse:add(nn.Linear(opt.imageHiddenSize, opt.hiddenSize))
RNN 是 一瞥網路和遞歸層結合的地方,rnn 模組的輸出是隱藏狀態 h[t],其中 t 為時間步長索引。我們使用 rnn 套件來建置
-- rnn recurrent layer
recurrent = nn.Linear(opt.hiddenSize, opt.hiddenSize)
-- recurrent neural network
rnn = nn.Recurrent(opt.hiddenSize, glimpse, recurrent, nn[opt.transfer](), 99999)
我們已經在上方看過定位網路,但它再次出現在這裡
-- actions (locator)
locator = nn.Sequential()
locator:add(nn.Linear(opt.hiddenSize, 2))
locator:add(nn.HardTanh()) -- bounds mean between -1 and 1
locator:add(nn.ReinforceNormal(2*opt.locatorStd)) -- sample from normal, uses REINFORCE learning rule
locator:add(nn.HardTanh()) -- bounds sample between -1 and 1
locator:add(nn.MulConstant(opt.unitPixels*2/ds:imageSize("h")))
定位器的任務是,根據前一個隱藏狀態 h[t-1],為下一個位置 l[t](或動作)取樣,亦即 rnn 的前一個輸出。對於第一步,我們使用 h[0] = 0(一個零張量)作為前一個隱藏狀態。您應該還要將注意力集中於 opt.unitPixels 這個變數,因為它非常重要,而且未在論文中說明。這個變數基本上說明了每個閃視的中心到達中心有多遠(以像素為單位),以邊界為基準。因此,如果值為 13(預設值),表示閃視的中心可能介於第 2 和第 27 個像素之間(對於 1x28x28 MNIST 範例)。所以,如果 opt.unitPixels = 14,那角隅的閃視將有較少的零相鄰值。
我們需要將 rnn 和 locator 封裝到將擷取 RAM 模型精華的模組中。因此,我們決定實作一個模組,將完整影像視為輸入,並輸出隱藏狀態順序 h。如模組名稱表示,這是一個一般用途的 RecurrentAttention 模組
attention = nn.RecurrentAttention(rnn, locator, opt.rho, {opt.hiddenSize})
這個模組為一般用途,因此您可以搭配 LSTM 模組,以及不同的閃視或定位器模組使用。只要這些模組分別保留相同的 {輸入 、 動作} -> 輸出 介面(閃視),當然,還要使用 REINFORCE 演算法(定位器)。
接著,我們透過堆疊一個分類器在 RecurrentAttention 模組之上來建立一個代理程式。分類器的輸入是最後的隱藏狀態 h[T],其中 T 是總時間步驟數(亦即要執行的閃視數)。
-- model is a reinforcement learning agent
agent = nn.Sequential()
agent:add(nn.Convert(ds:ioShapes(), 'bchw'))
agent:add(attention)
-- classifier :
agent:add(nn.SelectTable(-1))
agent:add(nn.Linear(opt.hiddenSize, #ds:classes()))
agent:add(nn.LogSoftMax())
您可能會想起來,REINFORCE 演算法需要基準獎勵 b 嗎?這正是它發生的情況(是的,需要一點 nn 功夫)
-- add the baseline reward predictor
seq = nn.Sequential()
seq:add(nn.Constant(1,1))
seq:add(nn.Add(1))
concat = nn.ConcatTable():add(nn.Identity()):add(seq)
concat2 = nn.ConcatTable():add(nn.Identity()):add(concat)
-- output will be : {classpred, {classpred, basereward}}
agent:add(concat2)
在這一點上,模型已準備好進行訓練。 agent 執行個體實際上就是論文中詳細說明的 RAM 模型。
訓練
在這之後,訓練非常直接。可以使用預設的超參數來啟動腳本。應執行 1-2 次執行個體,找到一個驗證極小值,以複製論文的 MNIST 測試結果。我們仍在複製翻譯過和雜亂的 MNIST 結果。
結果
在論文中,7 次瞥視在 MNIST 上獲得了 1.07% 的錯誤。在 853 個訓練時期後,我們得到了 0.85% 的錯誤(當然是在驗證組上提早停止)。這裡有一些瞥視序列。請注意第一幀如何從同一個位置開始

這是模型對這些序列的看法
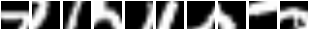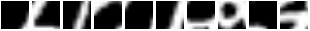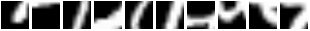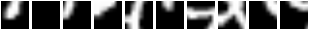
所以 REINFORCE 基本很好地教導模組將注意力集中在給定不同輸入的不同區域上。一個失敗模式(糟糕)會看到模型執行

在那個特定案例中,opt.unitPixels 被設定為 6 而不是 12(所以注意力限制在影像中心的區域)。你不想要這樣,因為這表示注意與輸入條件無關(即愚蠢)。
以下是 Translated MNIST 資料集的一些結果

對於這個資料集,影像大小為 1x60x60,每個影像都包含一個隨機放置的 1x28x28 MNIST 數字。3x12x12 瞥視使用 3 個比例的深度,其中每個連續的方塊高度和寬度是前一個的兩倍。在 Translated MNIST 資料集上使用 7 次瞥視,經過 683 個時期的訓練,我們獲得了 0.92% 的錯誤。該論文分別達到 6 和 8 次瞥視的 1.22% 和 1.2% 錯誤。獲取這些結果所使用的確切指令
th examples/recurrent-visual-attention.lua --cuda --dataset TranslatedMnist --unitPixels 26 --learningRate 0.001 --glimpseDepth 3 --maxTries 200 --stochastic --glimpsePatchSize 12
注意:你可以使用評量腳本評估模型。它會產生瞥視序列範例,並列印測試組的混淆矩陣結果。
結論
這篇部落格討論使用 REINFORCE 演算法的視覺注意力遞迴模型的具體實作。REINFORCE 演算法非常強大,因為它能夠使用深度學習瞭解不可微分的標準。然而,和許多深度學習演算法一樣,它確實需要一段很長的時間收斂。儘管如此,如這裡和原始論文中所展示的,訓練一個模型以瞭解將注意力集中在哪裡的,可以提供顯著的效能改善。
參考文獻
- Volodymyr Mnih, Nicolas Heess, Alex Graves, Koray Kavukcuoglu,視覺注意力的遞迴模型,NIPS 2014
- Gregor, Karol, et al.,DRAW:用於產生影像的遞迴神經網路,Arxiv 2015
- Williams, Ronald J.,連接主義強化的非統計梯度演算法,機器學習 8.3-4 (1992): 229-256。
- Rumelhart, David E., Geoffrey E. Hinton, and Ronald J. Williams. 透過誤差迴向學習內部表徵,No. ICS-8506