以十億個單字進行語言模型化
在我們上一篇貼文中,介紹了一個結合強化學習和遞迴神經網路的視覺注意力遞迴模型。在這個 Torch 部落格貼文中,我們使用雜訊對比估計 (NCE) [2],在 Google 十億字元 (GBW) 資料集 [7] 上訓練一個以多 GPU 遞迴神經網路為基礎的語言模型 (RNNLM)。這裡呈現的成果是由 Element-Research 經過好幾個月斷斷續續的研究才完成的。龐大的資料集讓我們必須貢獻一些新穎的開源 Torch 模組、標準,甚至是一個多 GPU 張量。我們也提供指令碼,讓您可以訓練和評估您的語言模型。
如果您只對產生的範例、困惑度和學習曲線有興趣,請直接跳到結果區段。
文字模型與字元語言模型
在最近幾個月中,您可能會注意到大家對生成字元等級 RNNLM(例如 char-rnn 和較新的torch-rnn)越來越有興趣。這些模型非常有趣,因為它們可用於產生以下一類的字元序列
<post>
Diablo
<comment score=1>
I liked this game so much!! Hope telling that numbers' benefits and
features never found out at that level is a total breeze
because it's not even a developer/voice opening and rusher runs
the game against so many people having noticeable purchases of selling
the developers built or trying to run the patch to Jagex.
</comment>
上面這段文字是使用reddit 留言的範本,一次產生一個字元。如您所見,產生的文字,乍看之下,其一般結構看起來不錯。標記適當打開和關閉。第一句看起來不錯:我很喜歡這個遊戲!而且與貼文的子版塊相關:Diablo。但是,讀完後面的內容,我們可以開始看出字元等級語言模型的限制。個別單字的拼寫看起來很不錯,但是下一句的意思卻很難理解(而且很長)。
在這個部落格貼文中,我們將會展示如何使用 Torch 訓練一個大規模的字詞等級語言模型以產生獨立的句子。字詞等級模型比字元等級模型有重要的優勢。請以以下序列為例(羅伯特·海萊茵的一句名言)
Progress isn't made by early risers. It's made by lazy men trying to find easier ways to do something.
在進行符號化後,詞彙級模型視此順序包含 22 個符號。反之,字元級視此順序包含 102 個符號。這個較長的順序使得字元模型的工作比詞彙模型困難,這是因為它必須考量更多符號間更多時間步長的依存性。字元語言模型的另一個問題在於它們需要學習拼寫,除了語法、語意等。無論如何,詞彙語言模型通常會比字元模型有較低的錯誤率。[8]
字元模型相較於詞彙語言模型的主要優勢在於它們有極小的詞彙表。舉例來說,GBW 資料集會包含約 800 個字元,相較於 80 萬個詞彙(在修剪低頻率符號後)。在實務上來說,這表示字元模型需要的記憶體較小,並且比它們的詞彙表對應項有更快的推論速度。另一項優勢在於它們不需要符號化作為前處理步驟。
遞迴神經網路語言模型
我們的任務是建置一個語言模型,它最大化在句子中前幾個詞彙的歷史給定下,下一個詞彙的可能性。下列圖示說明了一個簡單遞歸神經網路 (Simple RNN)語言模型的運作方式
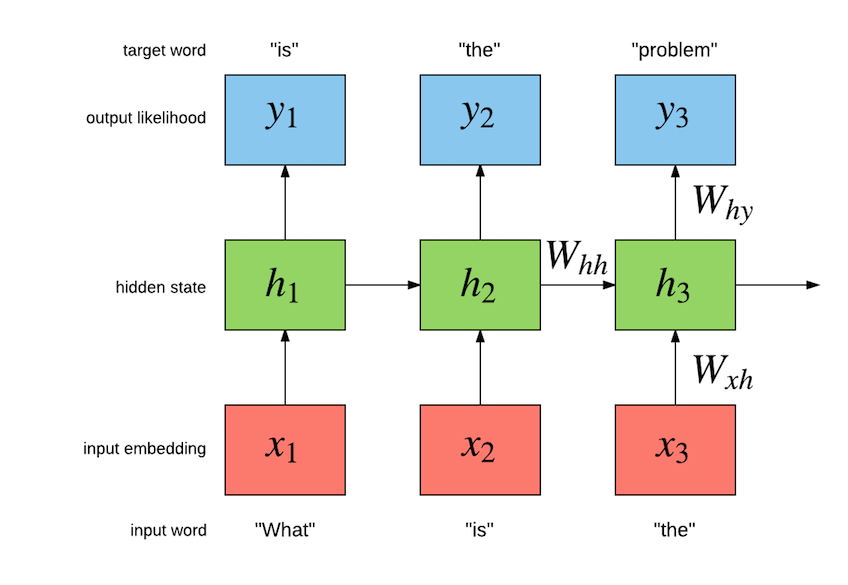
確切的實作如下所示
h[t] = σ(W[x->h]x[t] + W[h->h]h[t−1] + b[1->h]) (1)
y[t] = softmax(W[x->y]h[t] + b[1->y]) (2)
對於此特定範例,模型應在給定「是什麼」的情況下最大化「是」的機率,接著在給定「是」的情況下最大化「那個」,依此類推。簡易 RNN 具有內部隱藏狀態 h[t],而此狀態會綜合迄今輸入的序列,以最大化序列中剩餘字詞的機率。在內部,簡易 RNN 具有由輸入至隱藏(字詞嵌入)、隱藏至隱藏(遞迴連線)及隱藏至輸出的參數(會輸入至 softmax 的輸出嵌入)。輸入至隱藏的參數包含 LookupTable,可將每個字詞表示成向量。這些向量組成了字詞的嵌入空間。輸入 x[t] 至 LookupTable 的內容,是與字詞 w[t] 關聯的唯一整數。此字詞的嵌入向量透過編制嵌入空間 W[x->h](我們以 W[x->h]x[t] 表示此空間)取得。隱藏至隱藏的參數透過產生 h[t] 的隱藏狀態來模擬字詞的時間相依性,給定 h[t-1] 及 x[t]。這會在 h[t] 為 h[t-1](及字詞 x[t])之函數時產生實際的遞迴。隱藏至輸出的層會執行仿射轉換(也就是一個 Linear 模組:W[x->y]h[t] + b[1->h]),接著再執行 softmax。這是為了在給定先前的字詞(由隱藏狀態 h[t] 體現)的情況下,估計下一個字詞的機率分佈 y[t]。標準是針對下一個字詞 w[t+1] 在給定先前字詞的情況下,最大化下一個字詞的機率:P(w[t+1]|w[1],w[2],...,w[t])。
使用 rnn 套件(請參閱 簡易 RNN 範例)可輕易建置簡易 RNN,但這並非可用來建模語言的唯一模型類別。還有更進階的長短期記憶 (LSTM) 模型 [3],[4],[5],其具有特殊閘控元件,可在更長的序列中促進梯度的反向傳播。
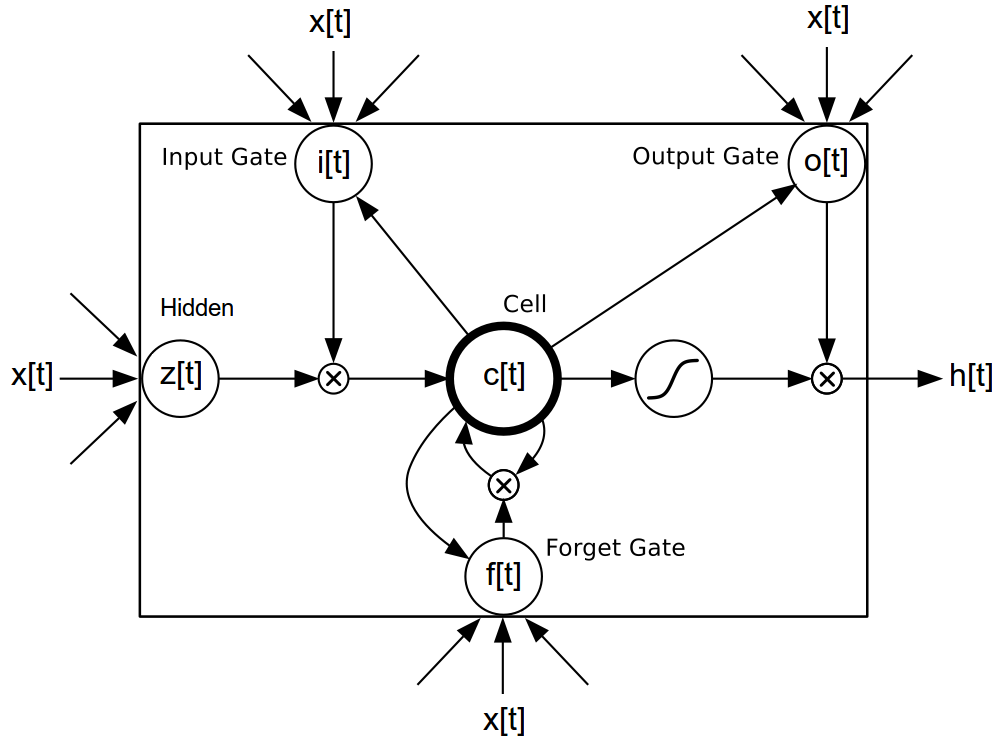
確切的實作如下所示
i[t] = σ(W[x->i]x[t] + W[h->i]h[t−1] + b[1->i]) (3)
f[t] = σ(W[x->f]x[t] + W[h->f]h[t−1] + b[1->f]) (4)
z[t] = tanh(W[x->c]x[t] + W[h->c]h[t−1] + b[1->c]) (5)
c[t] = f[t]c[t−1] + i[t]z[t] (6)
o[t] = σ(W[x->o]x[t] + W[h->o]h[t−1] + b[1->o]) (7)
h[t] = o[t]tanh(c[t]) (8)
主要的優點是,LSTM 可以學習時間間距較長的字詞之間的相依性。由於不同的閘控元件可以在反向傳播期間保留梯度,因此它不像消失梯度問題那麼容易發生。若要建立 LM,字詞嵌入(等式 1 中的 W[x->h]x[t])會輸入 LSTM,而結果的隱藏狀態會輸入等式 2。
語言模型的誤差傳統上利用困惑度來衡量。困惑度是衡量模型在看到一連串文字時的驚訝程度。如果我們將一連串文字輸入模型,模型可以針對每一個連續的文字,以高機率預測下一個文字,那麼這個模型的困惑度就低。如果一個長度為 T 的文字序列 s 中的第 t 個字,利用索引 s[t] 來標示,其透過模型推論的機率為 y[t],那麼該字的機率為 y[t][s[t]],這段文字序列的困惑度為
log(y[1][s[1]) + log(y[2][s[2]) + ... + log(y[T][s[T])
PPL(s,y) = exp( -------------------------------------------------------- )
-T
困惑度愈低,愈好。
載入 Google 十億字元資料集
對於我們的字元等級語言模型,我們使用 GBW 資料集。此資料集與 Penn Tree Bank 不同之處在於,它讓句子彼此獨立。因此我們的資料集會包含一組獨立且長度不一的序列。我們可以透過 dataload 套件輕鬆載入這個資料集
local dl = require 'dataload'
local train, valid, test = dl.loadGBW(batchsize)
如果硬碟中沒有發現資料,上述程式碼會自動下載資料,並回傳訓練、驗證與測試資料集。這些都是 dl.MultiSequence 實例,其建構函式如下
dataloader = dl.MultiSequence(sequences, batchsize)
sequences 參數為 Lua 表格或 tds.Vector,其中每個元素都是包含一個獨立序列的張量。例如
sequences = {
torch.LongTensor{424,158,115,667,28,505,228},
torch.LongTensor{389,456,188},
torch.LongTensor{77,172,760,687,552,529}
}
batchsize = 2
dataloader = dl.MultiSequence(sequences, batchsize)
請注意,各序列長度不一。與所有 dl.DataLoader 子類別一樣,dl.MultiSequence 載入程式提供了一個方法,可以從資料集中子取樣一批 inputs 和 targets
local inputs, targets = dataloader:sub(1, 10)
sub 方法使用 start 和 end 索引標示要索引的子序列。在函式內,這些索引只會用於決定所要求多重序列的長度 (seqlen)。對 sub 的每一次後續呼叫都會回傳與前一次呼叫相連的多重序列。
回傳的 inputs 和 targets 分別是 seqlen x batchsize [x inputsize] 張量,包含兩組多重序列,每組多重序列包含八個時間步長。從 inputs 開始:
print(inputs)
0 0
424 77
158 172
115 760
667 687
28 552
505 0
0 424
[torch.DoubleTensor of size 8x2]
每一個欄都是一個向量,包含多個序列,也稱為多重序列。獨立的序列會以零隔開。在下一段,我們將看到 rnn 套件如何使用這些以零遮罩的時間步長,在獨立序列之間有效地遺忘其隱藏狀態(在欄的粒度)。現在,請注意原本的 sequences,如何包含在回傳的 inputs 中,並以零隔開。
<目標> 與 <輸入> 類似,但使用 1 的遮罩來分隔序列(否則,<ClassNLLCriterion> 會抱怨)。在語言模型中,任務通常是預測下一個字,因此 <目標> 會比相應的 <輸入> 延遲一個時間步驟
print(targets)
1 1
158 172
115 760
667 687
28 552
505 529
228 1
1 158
[torch.DoubleTensor of size 8x2]
<dl.loadGBW> 呼叫回傳的 <訓練>、<驗證> 及 <測試> 具有與上述相同的屬性。唯一不同的是,資料集大很多(有一個十億個字)。為了除錯等目的,我們可以選擇載入訓練集的一個較小子集合。這樣載入的速度會比預設訓練集檔案快很多
local train, valid, test = dl.loadGBW({2,2,2}, 'train_tiny.th7')
上述會對所有集合使用 2 的 <批次大小>。使用 subiter 會讓迭代資料載入器更輕鬆
local seqlen, epochsize = 3, 10
for i, inputs, targets in train:subiter(seqlen, epochsize) do
print("T = " .. i)
print(inputs)
end
會輸出
T = 3
0 0
793470 793470
211427 6697
[torch.DoubleTensor of size 3x2]
T = 6
477149 400396
720601 213235
660496 368322
[torch.DoubleTensor of size 3x2]
T = 9
676607 61007
161927 767587
248714 635004
[torch.DoubleTensor of size 3x2]
T = 10
280570 130510
[torch.DoubleTensor of size 1x2]
我們也可以將上述批次傳回一個大區塊
train:reset() -- resets the internal sequence iterator
print(train:sub(1,10))
0 0
793470 793470
211427 6697
477149 400396
720601 213235
660496 368322
676607 61007
161927 767587
248714 635004
280570 130510
[torch.DoubleTensor of size 10x2]
請注意上述小批次如何與這個大區塊對齊。這表示資料會依序迭代。
GBW 資料集中的每個句子都封裝在 <S> 和 </S> 標記中,分別表示序列的開始和結束。每個標記都對應到一個整數。舉例而言,您可以在上述範例中看到 <S> 對應到整數 793470。現在對我們的資料集很有信心了,讓我們來看一下模型。
建立多層 LSTM
在本節中,我們會專注在實際建置多層 LSTM 的工作上。我們會在過渡到輸出層之後,從輸入層開始介紹 NCE。
<lm> 模型的輸入層是一個查詢表
lm = nn.Sequential()
-- input layer (i.e. word embedding space)
local lookup = nn.LookupTableMaskZero(#trainset.ivocab, opt.inputsize)
lm:add(lookup) -- input is seqlen x batchsize
作為 <LookupTable> 的子類別,我們使用 LookupTableMaskZero 來學習詞嵌入。最主要的差別在於它支援零索引,會作為零張量傳遞。接著,我們有實際的多層 LSTM 實作,它使用 SeqLSTM 模組
local inputsize = opt.inputsize
for i,hiddensize in ipairs(opt.hiddensize) do
local rnn = nn.SeqLSTM(inputsize, hiddensize)
rnn.maskzero = true
lm:add(rnn)
if opt.dropout > 0 then
lm:add(nn.Dropout(opt.dropout))
end
inputsize = hiddensize
end
正如 rnn-benchmarks 資料庫中展示的,<SeqLSTM> 實作非常快速。接下來,我們會將 SeqLSTM 的輸出(一個 <seqlen x 批次大小 x 輸出大小> 張量)拆分成一個表,其中包含針對每個時間步驟一個 <批次大小 x 輸出大小> 張量
lm:add(nn.SplitTable(1))
問題:輸出層的瓶頸
由於賓州樹庫資料集的字彙量僅有 10000 個字,因此相較之下比較容易用於建立字元級語言模型。輸出層在訓練和推理方面仍有足夠的計算能力,特別是對於 GPU 而言。對於這些較小的字彙量,輸出層基本上就是一個 線性 接著一個 SoftMax
outputlayer = nn.Sequential()
:add(nn.Linear(hiddensize, vocabsize))
:add(nn.SoftMax())
不過,當使用 GBW 資料集中包含的 793471 個字詞等龐大字彙量來訓練時,輸出層很快就會成為瓶頸。例如,如果您使用 批次大小 = 128(每個批次的序列數)和 序列長度 = 50(時間反向傳播的序列大小)來訓練模型,則該層的輸出將擁有 序列長度 x 批次大小 x 字彙量大小 的形狀,也就是 128 x 50 x 793471。對於一個 FloatTensor 或 CudaTensor,單一張量就會佔用 20GB 的記憶體!這個數字對於 gradInput(也就是對於輸入的梯度)來說可能會翻倍,而且由於 線性 和 SoftMax 都會儲存一個 輸出 的副本,所以還會再翻倍。
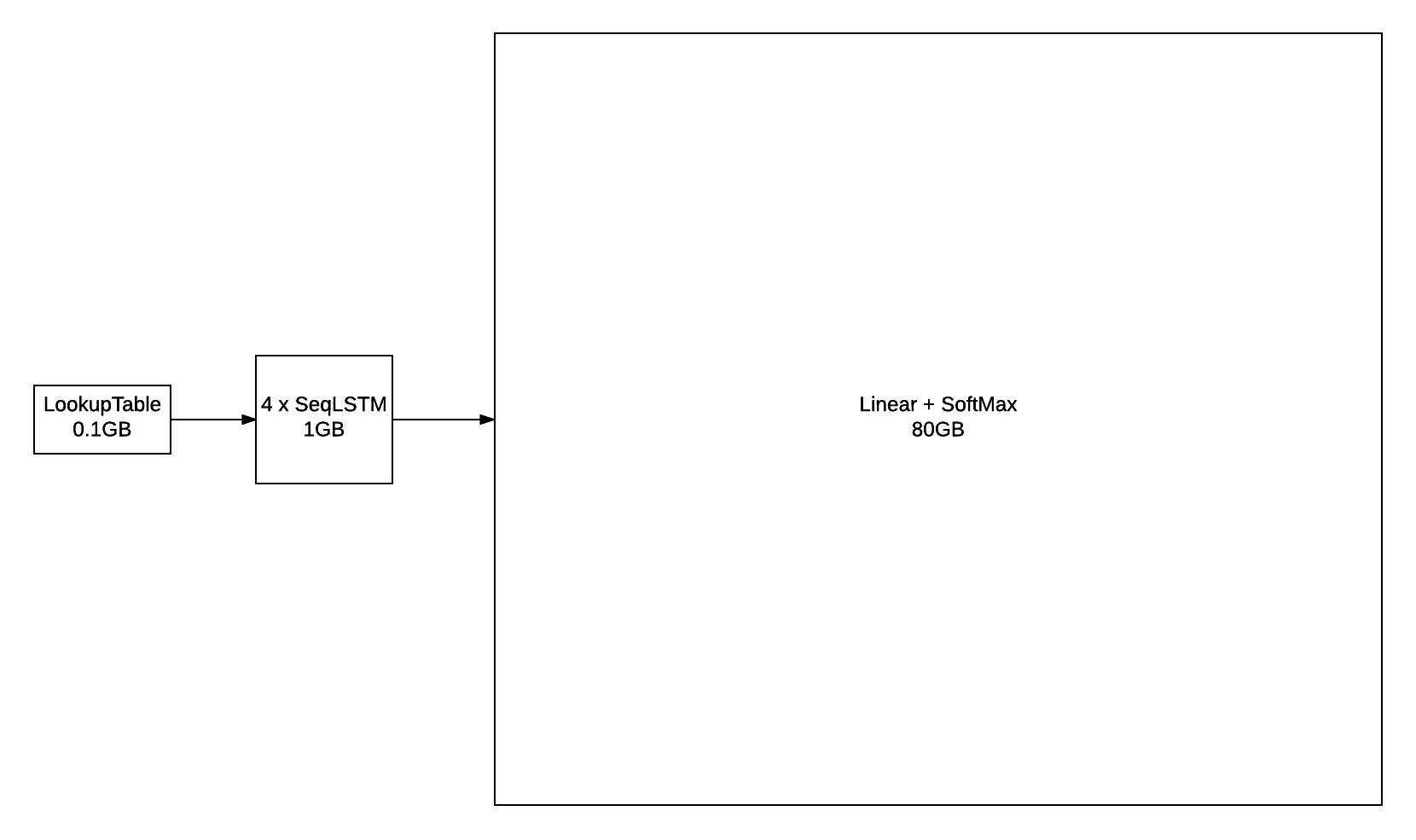
除了參數及其梯度之外,上述數據概述了序列長度為 50 的 4 層 LSTM 和 2048 個單元的近似記憶體使用量。即使您設法找到一種方法將 80GB 放置在 GPU 上(或在多個 GPU 上分配),但在合理的時程中透過這個 輸出層 進行前向/後向傳遞仍然是一個問題。
解決方案:雜訊對比估計
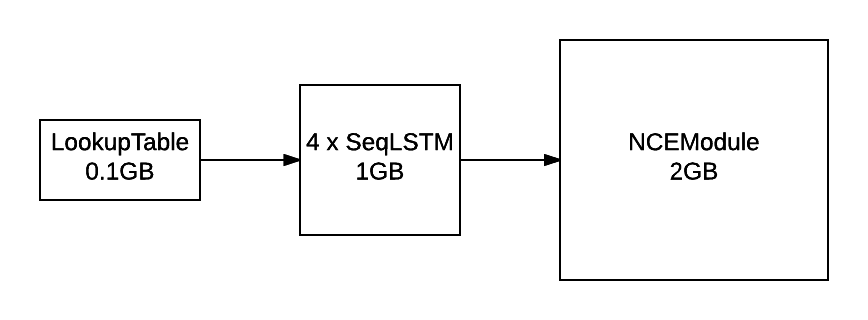
LM 的輸出層使用 NCE 來加速訓練並減少記憶體使用量
local unigram = trainset.wordfreq:float()
local ncemodule = nn.NCEModule(inputsize, #trainset.ivocab, opt.k, unigram, opt.Z)
-- NCE requires {input, target} as inputs
lm = nn.Sequential()
:add(nn.ParallelTable()
:add(lm):add(nn.Identity()))
:add(nn.ZipTable())
-- encapsulate stepmodule into a Sequencer
lm:add(nn.Sequencer(nn.MaskZero(ncemodule, 1)))
NCEModule 是一個更有效率的版本
nn.Sequential():add(nn.Linear(inputsize, #trainset.ivocab)):add(nn.LogSoftMax())
對於評估困惑度,此模式仍然導入 線性 + SoftMax。NCE 可用於在訓練過程中減少記憶體使用量(與上述數據比較)
連同 NCECriterion, NCEModule 會導入演算法,如 [1] 所述。我不會深入探討演算法的詳細資料,因為其中牽涉到許多數學概念,這些概念在參照論文中有更詳盡的說明。其運作方式是在每個目標字(我們希望最大化其可能性)中,會從雜訊分布(通常一元分布)中抽樣 k 個字。
請記住,softmax 基本上是
exp(x[i])
y[i] = --------------------------------- (9)
exp(x[1])+exp(x[2])+...+exp(x[n])
其中 x[i] 是輸出 線性 層的第 i 個輸出。上述分母會造成瓶頸,因為需要針對每個輸出 x[i] 計算 線性。對於字彙量為 n=797470 的字彙量而言,這將非常昂貴。NCE 在訓練過程中以常數 Z 取代等式 9 的分母,來解決這個問題
exp(x[i])
y[i] = ------------ (10)
Z
然 780;這樣並非訓 244;時實際發生的狀況,因為透過上述反向傳播無法為 j~=i(j 不等於 i)其中 x[j] 產生梯度。請注意,透過等式 9 反向傳播將為 Linear 的所有輸出 x 產生梯度(也就是所有 i)。等式 10 的另一個問題是沒有任何機制驅動 exp(x[1])+exp(x[2])+...+exp(x[n]) 逼近 Z。NCE 所採取的方式是將此問題制定成等式中可以包含 k 個雜訊範例,以確保某些(最多 k 個)負範例(也就是 x[j] 其中 j)取得梯度,以及等式 9 的分母逼近等式 10 的分母。這 k 個雜訊範例取樣自雜訊分配,也就是單詞分配。輸出層 Linear 只需要為目標和雜訊採樣的字詞運算,這也是效率提升之處。
上述 unigram 變數是一個大小為 793470 的張量,其中每個元 032;都是公司中相應字詞的頻率。使用類似 torch.multinomial 之類的函數針對這麼大的分配進行採樣,在訓 244;期間可能會造成瓶頸。因此我們在 torch.AliasMultinomial 中實作了一個更有效率的版本。後面的多項式採樣器需要比前 773;更長時間的設定時間,不過因為單詞分配是固定的,這並不成問題。
NCE 使用雜訊範例逼近正則化項 Z,其中輸出分配為 exp(x[i])/Z, 780; x[i] 是 Linear 對字詞 i 的輸出。對於 NCE 嘗試逼近的 Softmax, Z 是所有字詞 i' 的 exp(x[i']) 的總和。對於 NCE, Z 通常固定為 Z=1。我們的初步實驗發現,將 Z 設定為 Z=N*mean(exp(x[i]))(其中 N 是字詞數量, 780; mean 則是針對一小批字詞範例 i 估算)可以獲得更理想的 080;果,但這是因為我們未能適當初始化輸出層參數。
NCE 論文的一項值得留意的面向(儘管還有許多)是,它們常常遺漏說明這個參數初始化的重要性。設定 Z=1 只有在 NCEModule.bias 初始化為 bias[i] = -log(N) 時,才確實可行。儘管論文中未提及這一點(我聯繫上其中一位作者後得知),但 [2] 的作者使用的是這個值。
採樣每個時間步驟和每個批次列 k 個雜訊樣本,表示 NCEModule 在內部需要像 torch.baddbmm 那樣,使用某些內容來計算 output。參考文獻 [2] 實作一個較快的版本,其中僅繪製一次雜訊樣本,並在整個批次中使用(但仍適用於每個時間步驟)。這使程式碼快了一些,因為可以更有效率地使用 torch.addmm,而不是 torch.baddbmm。參考文獻 [2] 中描述的這個較快的 NCE 版本,是 NCEModule 的預設實作。採樣每個批次列可以透過 NCEModule.rownoise=true 開啟。
訓練及評估指令碼
本文提供的實驗使用三個腳本:兩個用於訓練(你只需要使用一個),一個用於評量。訓練腳本僅在使用的 GPU 量上有所不同。這兩個都對訓練語料庫訓練語言模型,並對驗證語料庫執行早期停止。評量腳本用於衡量訓練模型對測試語料庫的困惑度,或用於產生句子。
單一 GPU 訓練腳本
我們透過 noise-contrastive-estimate.lua 腳本來提供單一 GPU 的訓練腳本。在 12GB NVIDIA Titan X 上執行以下內容,在 321 個世代後,測試語料庫的困惑度應達到 65.6
th examples/noise-contrastive-estimate.lua --cuda --device 2 --startlr 1 --saturate 300 --cutoff 10 --progress --uniform 0.1 --seqlen 50 --batchsize 128 --trainsize 400000 --validsize 40000 --hiddensize '{250,250}' --k 400 --minlr 0.001 --momentum 0.9
產生的模型看起來會像這樣
nn.Serial @ nn.Sequential {
[input -> (1) -> (2) -> (3) -> output]
(1): nn.ParallelTable {
input
|`-> (1): nn.Sequential {
| [input -> (1) -> (2) -> (3) -> (4) -> output]
| (1): nn.LookupTableMaskZero
| (2): nn.SeqLSTM
| (3): nn.SeqLSTM
| (4): nn.SplitTable
| }
|`-> (2): nn.Identity
... -> output
}
(2): nn.ZipTable
(3): nn.Sequencer @ nn.Recursor @ nn.MaskZero @ nn.NCEModule(250 -> 793471)
}
若要減少約三分之一的記憶體用量,你可以設定動能為 0。
評量腳本
評量腳本可以用於衡量測試語料庫的困惑度或採樣獨立句子。若要評量一個已儲存的模型,你可以使用 evaluate-rnnlm.lua 腳本
th scripts/evaluate-rnnlm.lua --xplogpath /home/nicholas14/save/rnnlm/gbw:uranus:1466538423:1.t7 --cuda
你可以將 /home/nicholas14/save/rnnlm/gbw:uranus:1466538423:1.t7 替換成你自己的訓練模型的途徑。鑑於它必須使用效率較低的 Linear + SoftMax,因此評估測試語料庫的時間可能會很長,從而導致批次大小非常小(以免使用過多記憶體)。
評量腳本也可以用於從語言模型中產生樣本
th scripts/evaluate-rnnlm.lua --xplogpath /home/nicholas14/save/rnnlm/gbw:uranus:1466790001:1.t7 --cuda --nsample 200 --temperature 0.7
--nsample 旗標指定要抽樣的詞彙數。傳入語言模型的第一個詞彙是句首標籤 (<S>)。當出現句尾標籤 (</S>) 時,模型的隱藏狀態會設定為零,如此一來,每個句子都是獨立抽樣的。--temperature 旗標可以降低以使抽樣更確定。
<S> There were a number of players in the starting lineup during the season and in recent weeks , in recent years , some fans have been frustrated . </S>
<S> WASHINGTON ( Reuters ) - The government plans to cut greenhouse gases by as much as 12 % on the global economy , a new report said . </S>
<S> One of the most important things about the day was that the two companies had just been guilty of the same nature . </S>
<S> " It has been as much a bit of a public service as a public organisation . </S>
<S> In a nutshell , it 's not only the fate of the economy . </S>
<S> It was last modified at 23.31 GMT on Saturday 22 December 2009 . </S>
<S> He told the newspaper the prosecution had been treating the small boy as " a young man who was playing for a while . </S>
<S> " We are astounded that our employees are not made aware of the risks and risks they are pursuing during this period of time , " he said . </S>
<S> " I had a right to come up with the idea . </S>
多 GPU 訓練腳本
如同在前一節所觀察到的,訓練只有 250 個隱藏單元的 2 層 LSTM 不會產生最佳生成的樣本。模型需要的容量遠超過 12GB GPU 可以容納的容量。對於參數和它們的梯度,一個 4x2048 LSTM 模型需要以下事項:
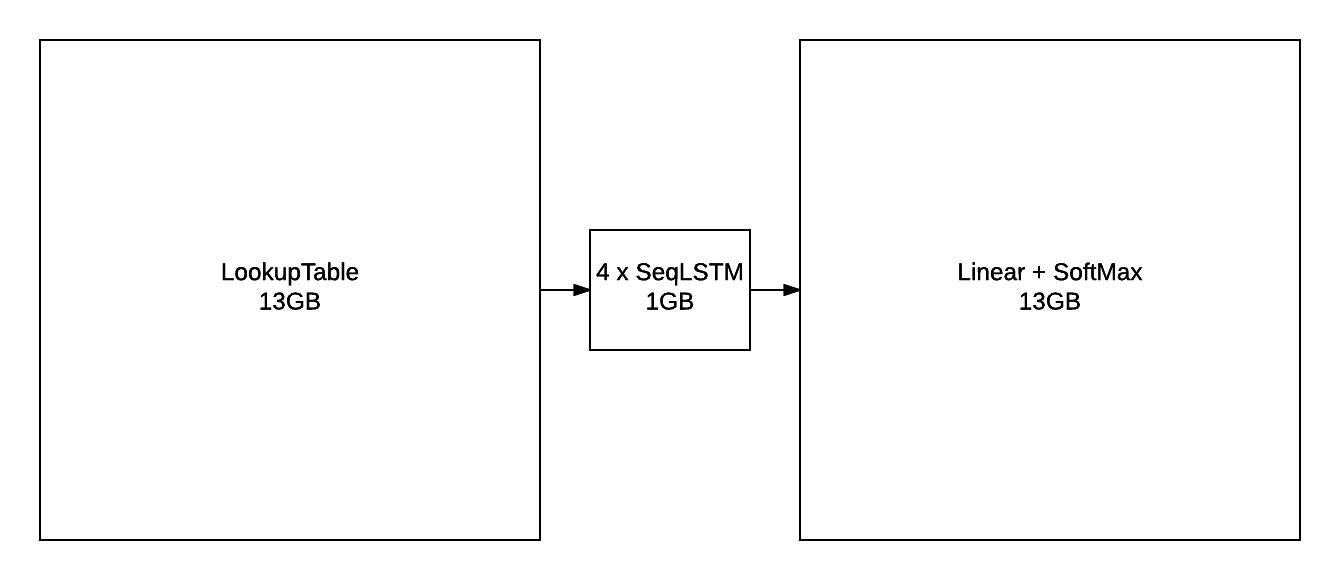
這不包括不同模組需要的中間緩衝區(在 NCE 區段 中有說明)。因此,解決方案當然是將模型分配到更多 GPU。multigpu-nce-rnnlm.lua 腳本提供用於在四個 GPU 上訓練語言模型。
它使用 GPU(我們對 nn 做出了貢獻)裝飾模組以將所有運算和記憶體託管在指定的裝置上。GPU 模組不會在不同 GPU 裝置上平行執行核心。但它確實允許我們在裝置上分配大型模型。
對於我們的 LM,輸入的詞彙嵌入(即 LookupTableMaskZeroNCEModule
lm = nn.Sequential()
lm:add(nn.Convert())
-- input layer (i.e. word embedding space)
local concat = nn.Concat(3)
for device=1,2 do
local inputsize = device == 1 and torch.floor(opt.inputsize/2) or torch.ceil(opt.inputsize/2)
local lookup = nn.LookupTableMaskZero(#trainset.ivocab, inputsize)
lookup.maxnormout = -1 -- prevent weird maxnormout behaviour
concat:add(nn.GPU(lookup, device):cuda()) -- input is seqlen x batchsize
end
基本上,嵌入空間會分成兩個表格。對於一個 2048 單位嵌入空間,一半,也就是 1024 個單位,位於兩個裝置中的每個裝置。我們使用 Concat 在 forward
對於隱藏層(即 SeqLSTM
local inputsize = opt.inputsize
for i,hiddensize in ipairs(opt.hiddensize) do
local rnn = nn.SeqLSTM(inputsize, hiddensize)
rnn.maskzero = true
local device = i <= #opt.hiddensize/2 and 1 or 2
lm:add(nn.GPU(rnn, device):cuda())
if opt.dropout > 0 then
lm:add(nn.GPU(nn.Dropout(opt.dropout), device):cuda())
end
inputsize = hiddensize
end
lm:add(nn.GPU(nn.SplitTable(1), 3):cuda())
由於 NCEModule 無法像 LookupTableMaskZero 那樣容易平行處理,因此要取得分配更為困難。我們的解決方法是在 weight 上提供一個簡單的 multicuda() 方法,用於在不同裝置上分配 gradWeight。這是透過將 weight 張量與我們自己的 : torch.MultiCudaTensor 交換,實現的。Lua 沒有嚴格的型別檢查系統,因此,您可以透過建置具有相同方法的 torch.class 表格,並製作一個假的張量。為了省時,目前的 MultiCudaTensor 版本僅支援 NCEModule 所需的操作。這種方法的優點在於它只需要對 NCEModule 進行最小的變更,並保持向後相容性,而不需冗餘程式碼或過度重構。
-- output layer
local unigram = trainset.wordfreq:float()
ncemodule = nn.NCEModule(inputsize, #trainset.ivocab, opt.k, unigram, opt.Z)
ncemodule:reset() -- initializes bias to get approx. Z = 1
ncemodule.batchnoise = not opt.rownoise
-- distribute weight, gradWeight and momentum on devices 3 and 4
ncemodule:multicuda(3,4)
-- NCE requires {input, target} as inputs
lm = nn.Sequential()
:add(nn.ParallelTable()
:add(lm):add(nn.Identity()))
:add(nn.ZipTable())
-- encapsulate stepmodule into a Sequencer
local masked = nn.MaskZero(ncemodule, 1):cuda()
lm:add(nn.GPU(nn.Sequencer(masked), 3, opt.device):cuda())
若要重現 [2] 中的結果,請執行下列操作:
th examples/multigpu-nce-rnnlm.lua --startlr 0.7 --saturate 300 --minlr 0.001 --cutoff 10 --progress --uniform 0.1 --seqlen 50 --batchsize 128 --trainsize 400000 --validsize 40000 --hiddensize '{2048,2048,2048,2048}' --dropout 0.2 --k 400 --Z 1 --momentum -1
與這篇論文有下列顯著差異:
- 使用 梯度範數裁剪 [3](其
cutoff範數為 10),以抵銷梯度爆炸和消失。 - 使用適應性學習率行程表(這點並未在論文中說明)。我們以學習率 0.7(他們也是從此處開始)線性遞減,使它在 300 個時期後達到 0.001。
- 我們使用
k=400範例,而他們使用k=100。為何如此?我沒有看到什麼重大速度下降,為何不呢? - 我們使用
seqlen=50的序列長度,進行截斷 BPTT。他們使用 100(同樣的,論文中未提及)。資料集中句子的平均長度為 27,因此 50 已綽綽有餘。
我們也如同他們一樣,在 LSTM 層之間使用 dropout=0.2。這是產生的模型外觀:
nn.Serial @ nn.Sequential {
[input -> (1) -> (2) -> (3) -> output]
(1): nn.ParallelTable {
input
|`-> (1): nn.Sequential {
| [input -> (1) -> (2) -> (3) -> (4) -> (5) -> (6) -> (7) -> (8) -> (9) -> (10) -> (11) -> (12) -> output]
| (1): nn.Convert
| (2): nn.GPU(2) @ nn.Concat {
| input
| |`-> (1): nn.GPU(1) @ nn.LookupTableMaskZero
| |`-> (2): nn.GPU(2) @ nn.LookupTableMaskZero
| ... -> output
| }
| (3): nn.GPU(2) @ nn.Dropout(0.2, busy)
| (4): nn.GPU(1) @ nn.SeqLSTM
| (5): nn.GPU(1) @ nn.Dropout(0.2, busy)
| (6): nn.GPU(1) @ nn.SeqLSTM
| (7): nn.GPU(1) @ nn.Dropout(0.2, busy)
| (8): nn.GPU(2) @ nn.SeqLSTM
| (9): nn.GPU(2) @ nn.Dropout(0.2, busy)
| (10): nn.GPU(2) @ nn.SeqLSTM
| (11): nn.GPU(2) @ nn.Dropout(0.2, busy)
| (12): nn.GPU(3) @ nn.SplitTable
| }
|`-> (2): nn.Identity
... -> output
}
(2): nn.ZipTable
(3): nn.GPU(3) @ nn.Sequencer @ nn.Recursor @ nn.MaskZero @ nn.NCEModule(2048 -> 793471)
}
結果
在具有 2048 隱藏單元的 4 層 LSTM 中,[1] 在 GBW 測試集中獲得 43.2 perplexity。在驗證集的一個子集中提早停止(在 100 個訓練時期,其中 1 個時期為 128 個序列 x 40 萬個單詞/序列)之後,我們的模型能夠達到 40.61 perplexity。
這個模型在 4x12GB NVIDIA Titan X GPU 上執行。訓練需要約 40GB 的記憶體,分配橫跨 4 個 GPU 裝置,並需經過 2-3 星期的訓練。正如原始論文所示,我們不使用動能,因為它提供的益處較小,且需要 1/2 倍以上的記憶體。
訓練速度約為每秒 3800 個單詞。
學習曲線
以下是上述 4x2048 LSTM 模型的學習曲線。圖形繪製了模型的 NCE 訓練和驗證錯誤,這是錯誤輸出,但是 NCEModule。測試集錯誤沒有繪製,因為對於任何一個世代,測試集推論都需要大約 3 小時,因為測試集推論中使用了具有 batchsize=1 的 Linear + SoftMax。
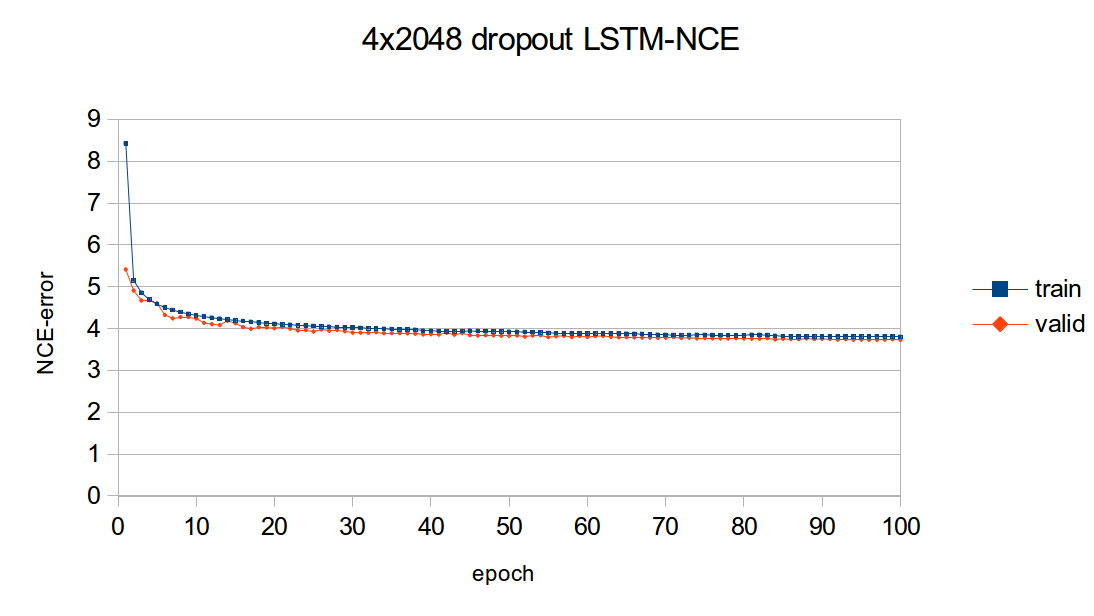
可以看出,大部分的學習是發生在第一個世代。儘管如此,訓練和驗證錯誤仍然持續在訓練過程中減少。
下圖比較了小型 2x250 LSTM(沒有中斷)以及大型 4x2048 LSTM(有中斷)的驗證學習曲線(同樣地,是 NCE 錯誤)。
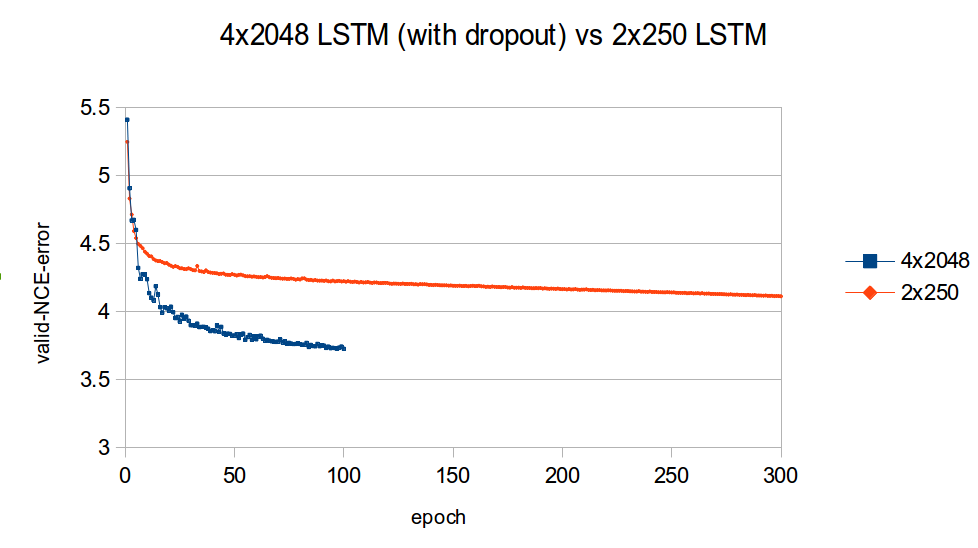
我覺得這張圖表令我印象深刻的是,容量較高的模型如何快速擊敗容量較低的模型。這清楚地證明了在最佳化大型語言模型時,容量的重要性。
產生句子
以下是獨立從 4 層 LSTM 採樣而來的句子,其中具有 溫度 或 0.7
<S> The first , for a lot of reasons , is the " Asian Glory " : an American military outpost in the middle of an Iranian desert . </S>
<S> But the first new stage of the project will be a new <UNK> tunnel linking the new terminal with the new terminal at the airport . </S>
<S> The White House said Bush would also sign a memorandum of understanding with Iraq , which will allow the Americans to take part in the poll . </S>
<S> The folks who have campaigned for his nomination know that he is in a fight for survival . </S>
<S> The three survivors , including a woman whose name was withheld and not authorized to speak , were buried Saturday in a makeshift cemetery in the town and seven people were killed in the town of Eldoret , which lies around a dozen miles ( 40 kilometers ) southwest of Kathmandu . </S>
<S> The art of the garden was created by pouring water over a small brick wall and revealing that an older , more polished design was leading to the creation of a new house in the district . </S>
<S> She added : " The club has not made any concession to the club 's fans and was not notified of the fact they had reached an agreement with the club . </S>
<S> The Times has learnt that the former officer who fired the fatal shots must have known about the fatal carnage . </S>
<S> Obama supporters say they 're worried about the impact of the healthcare and energy policies of Congress . </S>
<S> Not to mention the painful changes to the way that women are treated in the workplace . </S>
<S> The dollar stood at 14.38 yen ( <UNK> ) and <UNK> Swiss francs ( <UNK> ) . </S>
<S> The current , the more intractable <UNK> , the <UNK> and the <UNK> about a lot of priorities . </S>
<S> The job , which could possibly be completed in 2011 , needs to be approved in a new compact between the two companies . </S>
<S> " The most important thing for me is to get back to the top , " he said . </S>
<S> It was a one-year ban and the right to a penalty . </S>
<S> The government of president Michelle Bachelet has promised to maintain a " strong and systematic " military presence in key areas and to tackle any issue of violence , including kidnappings . </S>
<S> The six were scheduled to return to Washington on Wednesday . </S>
<S> " It 's a ... mistake , " he said . </S>
<S> The government 's offensive against the rebels and insurgents has been criticized by the United Nations and UN agencies . </S>
<S> " Our <UNK> model is not much different from many of its competitors , " said Richard Bangs , CEO of the National Center for Science in the Public Interest in Chicago . </S>
<S> He is now a large part of a group of young people who are spending less time studying and work in the city . </S>
<S> He said he was confident that while he and his wife would have been comfortable working with him , he would be able to get them to do so . </S>
<S> The summer 's financial meltdown is the worst in decades . </S>
<S> It was a good night for Stuart Broad , who took the ball to Ravi Bopara at short leg to leave England on 88 for five at lunch . </S>
<S> And even for those who worked for them , almost everything was at risk . </S>
<S> The new strategy is all part of a stepped-up war against Taliban and al-Qaida militants in northwest Pakistan . </S>
<S> The governor 's office says the proposal is based on a vision of an outsider in the town who wants to preserve the state 's image . </S>
<S> " The fact that there is no evidence to support the claim made by the government is entirely convincing and that Dr Mohamed will have to be detained for a further two years , " he said . </S>
<S> The country 's tiny nuclear power plants were the first to use nuclear technology , and the first such reactors in the world . </S>
<S> " What is also important about this is that we can go back to the way we worked and work and fight , " he says . </S>
<S> And while he has been the star of " The Wire " and " The Office , " Mr. Murphy has been a careful , intelligent , engaging competitor for years . </S>
<S> On our return to the water , we found a large abandoned house . </S>
<S> The national average for a gallon of regular gas was $ 5.99 for the week ending Jan . </S>
<S> The vote was a rare early start for the contest , which was held after a partial recount in 26 percent of the vote . </S>
<S> The first one was a show of force by a few , but the second was an attempt to show that the country was serious about peace . </S>
<S> It was a little more than half an hour after the first reports of a shooting . </S>
<S> The central bank is expected to cut interest rates further by purchasing more than $ 100 billion of commercial paper and Treasuries this week . </S>
<S> Easy , it 's said , to have a child with autism . </S>
<S> He said : " I am very disappointed with the outcome because the board has not committed itself . </S>
<S> " There is a great deal of tension between us , " said Mr C. </S>
<S> The odds that the Fed will keep its benchmark interest rate unchanged are at least half as much as they were at the end of 2008 . </S>
<S> For them , investors have come to see that : a ) the government will maintain a stake in banks and ( 2 ) the threat of financial regulation and supervision ; and ( 3 ) it will not be able to raise enough capital from the private sector to support the economy . </S>
<S> The court heard he had been drinking and drank alcohol at the time of the attack . </S>
<S> " The whole thing is quite a bit more intense . </S>
<S> This is a very important project and one that we are working closely with . </S>
<S> " We are confident that in this economy and in the current economy , we will continue to grow , " said John Lipsky , who chaired the IMF 's board of governors for several weeks . </S>
<S> The researchers said they found no differences among how men drank and whether they were obese . </S>
<S> Even though there are many brands that have low voice and no connection to the Internet , the iPhone is a great deal for consumers . </S>
<S> The £ 7m project is a new project for the city of Milton Keynes and aims to launch a new challenge for the British Government . </S>
<S> But he was not without sympathy for his father . </S>
語法看起來相當合理,特別是將其與從 單一 GPU 2x250 LSTM 所獲得的先前結果相比較時。然而,在某些情況下,語意,亦即字詞的意義,並不好。例如,對我來說至少,這個句子
<S> Easy , it 's said , to have a child with autism . </S>
如果將 容易 取代為 不容易 會更說得通。
另一方面,像這樣的句子展示了良好的語意
<S> The government of president Michelle Bachelet has promised to maintain a " strong and systematic " military presence in key areas and to tackle any issue of violence , including kidnappings . </S>`.
蜜雪兒·巴舍雷 確實是一位智利總統。在她早年的生活中,她也曾 被軍人綁架,因此在綁架問題上立場強硬似乎有其道理。
以下是某些奇怪語意的範例
<S> Even though there are many brands that have low voice and no connection to the Internet , the iPhone is a great deal for consumers . </S>
關於 加載聲音 的第一部分對我來說毫無意義。而且我無法理解 許多與網際網路無關的品牌 如何與 對於消費者來說,iPhone 是個很棒的交易 有關。但是,當然地,所有這些句子都是獨立產生的,因此語言模型需要學習隨時產生意義。這是很困難的,因為即將產生的句子沒有語境。
無論如何,我對於這些結果感到相當滿意,因為它們肯定是我到目前為止所看過最自然的合成句子。
未來工作
我目前正在製作根據一個月 reddit.com 資料為基礎的語言模型資料集。每個序列基本上是一個 reddit 提交,包含一個 標題、自訂文字 (或 網址)、評分、作者 和一個 留言 串。這些序列遠比構成 GBW 資料集的句子長 (平均 205 個標記),平均有 26 個標記)。目前仍在訓練中,但為了引起你的興趣,以下是一個生成資料的範例(為清楚起見,增加了縮排與換行)
<SUBMISSION>
<AUTHOR> http://www.reddit.com/u/[deleted] </AUTHOR>
<SCORE> 0 </SCORE>
<TITLE>
[ WP ] You take a picture of a big bang .
You discover an alien that lives in the center of the planet in an unknown way .
You can say " what the fuck is that ? "
</TITLE>
<COMMENTS>
<CoMMeNT>
<ScoRE> 2 </ScoRE>
<AuTHoR> http://www.reddit.com/u/Nev2k </AuTHoR>
<BodY>
I have a question .
When i was younger , my parents had a house that had a living room in it .
One that was only a small portion of an entire level .
This was a month before i got my money .
If i was living in a house with a " legacy " i would make some mistakes .
When i was a child , i did n't know how to do shit about the house .
My parents got me into my own house and i never found a place to live .
So i decide to go to college .
I was so freaked out , i didnt have the drive to see them .
I never had a job , i was n't going anywhere .
I was so happy .
I knew i was going to be there .
I gave myself a job and my parents came .
That 's when i realized that i was in the wrong .
So i started to go .
I couldnt decide how long i wanted to live in this country .
I was so excited about the future .
I had a job .
I saved my money .
I did n't have a job .
I went to a highschool in a small town .
I had a job .
A job .
I did n't know what to do .
I was terrified of losing my job .
So i borrowed my $ 1000 in an hour .
I could n't afford to pay my rent .
I was so low on money .
I had my parents and i got into a free college .
I got in touch with my parents .
All of my friends were dead .
I was still with my family for a week .
I became a good parent .
I was a good choice .
When i got on my HSS i was going to go to my parents ' house .
I started to judge my parents .
I had a minor problem .
My parents .
I was so fucking bad .
My sister had a voice that was very loud .
I 'm sure my cousins were in a place where i could just hear my voice .
I felt like i was supposed to be angry .
I was so angry .
To cope with this .
My dad and i were both on break and i felt so alone .
I got unconscious and my mum left .
When I got to college , i was back in school .
I was a good kid .
I was happy .
And I told myself I was ready .
I told my parents .
They always talked about how they were going to be a good mom , and that I was going to be ready for that .
They always wanted to help me .
I did n't know what to do .
I had to .
I tried to go back to my dad , because I knew a lot about my mom .
I loved her .
I cared about her .
We cared for our family .
The time together was my only relationship .
I loved my heart .
And I hated my mother .
I chose it .
I cried . I cried . I cried . I cried . I cried . I cried . I cried .
The tears were gone .
I cried . I cried . I cried . I cried . I cried . I cried . I cried . I cried . I cried . I cried .
I do n't know how to do it .
I do n't know how to deal with it .
I ca n't feel my emotions .
I ca n't get out of bed .
I ca n't sleep .
I ca n't tell my friends .
I just need to leave .
I want to leave .
I hate myself .
I hate feeling like I 'm being selfish .
I feel like I 'm not good enough anymore .
I need to find a new job .
I hate that I have to get my shit together .
I love my job .
I 'm having a hard time .
Why do I need to get a job ?
I have no job .
I have n't been feeling good lately .
I feel like I 'm going to be so much worse in the long run .
I feel so alone .
I ca n't believe I 'm so sad about going through my entire life .
</BodY>
<AuTHoR> http://www.reddit.com/u/Scarbarella </AuTHoR>
</CoMMeNT>
</COMMENTS>
<SUBREDDIT> http://www.reddit.com/r/offmychest </SUBREDDIT>
<SELFTEXT>
I do n't know what to do anymore .
I feel like I 'm going to die and I 'm going to be sick because I have no more friends .
I do n't know what to do about my depression and I do n't know where to go from here .
I do n't know how I do because I know I 'm scared of being alone .
Any advice would be appreciated .
Love .
</SELFTEXT>
</SUBMISSION>
這個特殊的範例有點令人沮喪,但那可能是 offmychest 子版塊的性質。以開啟的 <SUBMISSION> 標記為條件,儘管這個生成的序列並非完美,但卻難以置信地有人的感覺。讀完留言後,我感覺自己讀了一篇真的(有點精神分裂的)人寫的故事。模擬人類創造力的能力是我之所以如此有興趣使用 reddit 資料進行語言模型的原因之一。
以下是一個比較不令人沮喪的範例,與 命運 這個電玩遊戲有關
<SUBMISSION>
<SUBREDDIT> http://www.reddit.com/r/DestinyTheGame </SUBREDDIT>
<TITLE>
Does anyone have a link to the Destiny Grimoire that I can use to get my Xbox 360 to play ?
</TITLE>
<COMMENTS>
<CoMMeNT>
<AuTHoR> http://www.reddit.com/u/CursedSun </AuTHoR>
<BodY>
I 'd love to have a weekly reset .
</BodY>
<ScoRE> 1 </ScoRE>
</CoMMeNT>
</COMMENTS>
<SCORE> 0 </SCORE>
<SELFTEXT>
I have a few friends who are willing to help me out .
If I get to the point where I 'm not going to have to go through all the weekly raids , I 'll have to " complete " the raid .
I 'm doing the Weekly strike and then doing the Weekly ( and hopefully also the Weekly ) on Monday .
I 'm not planning to get the chest , but I am getting my first exotic that I just got done from my first Crota raid .
I 'm not sure how well it would work for the Nightfall and Weekly , but I do n't want to loose my progress .
I 'd love to get some other people to help me , and I 'm open to all suggestions .
I have a lot of experience with this stuff , so I figured it 's a good idea to know if I 'm getting the right answer .
I 'm truly sorry for the inconvenience .
</SELFTEXT>
<AUTHOR> <OOV> </AUTHOR>
</SUBMISSION>
對於不熟悉這電玩的讀者,像 傳說、每週重設、團隊副本、災變任務、異域武器或裝甲 和 克羅塔團隊副本 等術語可能很奇怪。但這些都是遊戲詞彙的一部分。
這個特定的模型(具有中斷的 4x1572 LSTM)僅透過 50 個時間步驟反向傳播。我希望看到的結果是 留言 實際上回答了 標題 和 自訂文字 提出的問題。這是一個非常困難的語意問題,我希望 Reddit 資料集有助於解決。更多內容將在下一篇 Torch 網誌文章中提供。
參考文獻
- A Mnih, YW Teh,一個快速的簡單演算法,用於訓練神經機率語言模型
- B Zoph, A Vaswani, J May, K Knight,用於大 RNN 字彙表的簡單、快速、雜訊對比估計
- R Pascanu, T Mikolov, Y Bengio,訓練遞迴神經網路的難處
- S Hochreiter, J Schmidhuber,長短期記憶
- A Graves, A Mohamed, G Hinton,使用遞迴神經網路進行語音辨識
- K Greff, RK Srivastava, J Koutník,LSTM:一個搜尋空間的冒險之旅
- C Chelba, T Mikolov, M Schuster, Q Ge, T Brants, P Koehn, T Robinson,一個十億字基準,用於衡量統計語言模型的進展
- A Graves,使用遞迴神經網絡產生序列,table 1